
Last year we released our model deployment solution GAMS Engine One, which allows scheduling and running jobs on a central compute server via a REST API .
Engine One is the perfect add-on for a machine based GAMS license. It makes development and integration of complex modeling scenarios into IT environments much easier than before, and helps reduce development time and cost.
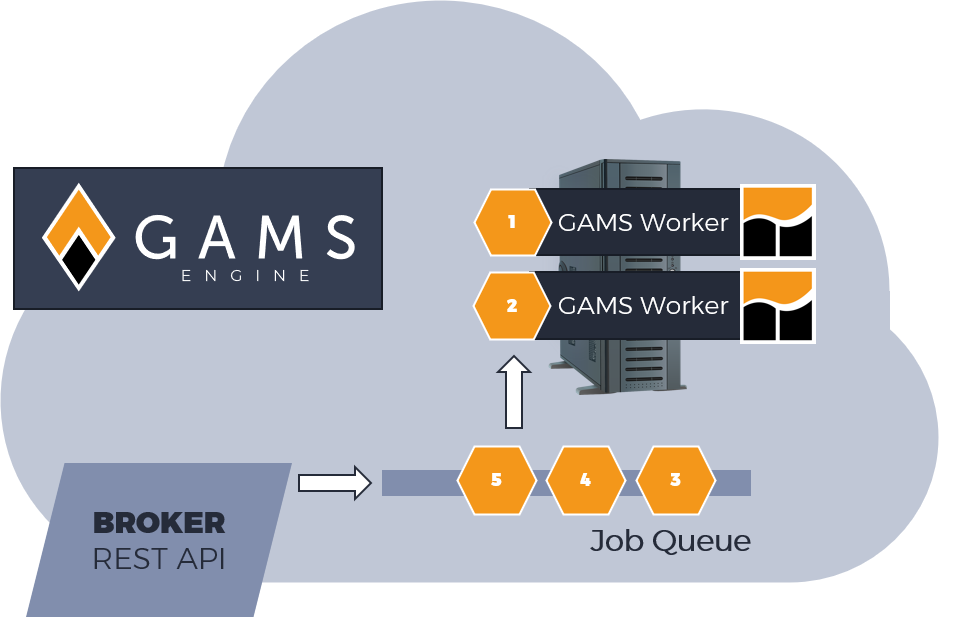
In the meantime, our developers took it up one notch, and we are very excited to present GAMS Engine SaaS, which transfers the principles and existing benefits of GAMS Engine One to the cloud. Based on Kubernetes, Engine SaaS makes use of the compute infrastructure offered by Amazon Web Services (AWS). As a consequence Engine SaaS has some major added benefits:
Horizontal Auto Scaling
Each GAMS job on Engine SaaS runs on it’s own virtual EC2 instance, or node in Kubernetes speak. In practical terms, AWS is able to provide an unlimited number of EC2 instances, so if you need to run one job, or 100 jobs in parallel, the infrastructure will scale automatically and without any complex configuration required on your part.
Instance Sizing
In addition to horizontal scaling, EC2 offers a wide range of instance types, both in terms of memory and CPU. We can therefore offer instances with as little as 16GB, up to a huge 4TB, and many sizes in between. The user can select a different instance type for each job, if that is required. We currently use the AWS z1d type for our smaller instances (up to 192GB), and the x1e types for everything above, up to 4TB.
Depending on your requirements, we can also add different instance types, for example if memory is not so important, but the number of cores is.
Zero Maintenance and High Reliability
We take care of operating the infrastructure for our customers, including keeping the software up to date. Our customers can focus on their end user application, and the optimization part “just works”, backed by our expertise and by the AWS infrastructure with it’s high reliability.
Simplified License Handling
IT admins have their own login to Engine SaaS, and can add an unlimited number of individual users. Each of those users will automatically inherit the same license the admin owns, so there is only one license to be aware of, and nothing the user needs to install.
A simple web user interface
The Engine SaaS web UI allows you to manage users, groups, namespaces, and jobs in a simple and intuitive way. This is great for getting started and getting a quick overview of what is happening in your account. You can also do all of those things directly using the Engine API , some of which I will demonstrate further down.
Pricing Considerations
If you have any questions regarding GAMS Engine, don’t hesitate to contact us at sales@gams.com . We are happy to schedule a demo for you and discuss your individual use case.
Among other things, we will then discuss with you your requirements in terms of compute hours and instance size requirements:
- What are the typical memory requirements for your GAMS jobs?
- How many hours each year do you expect to run those jobs?
- Which solvers will you need?
With this information we will create a tailor made package offer for you. This offer will include an hourly quota on your preferred instance size, be it 32GB or 4TB. You will always have the option to run jobs on other instance sizes on a case by case basis, giving you total flexibility.
The only thing you need to know is that there is a multiplier attached to each instance size, starting with a factor of 1 for the smallest instance, and then going up to higher values with larger instances. The multiplier determines how fast you burn through your quota relative to “wall time”. The exact multipliers will depend on the solvers you choose to license, and the total annual size of your quota.
A Simple Example in Python
I will use a contrived example to show the bare minimum of what you can do with GAMS Engine, in order to give you an idea of how straight-forward it is to use (if you know some Python and understand the requests library). You will see that it takes only a few lines of code to get started!
Assume we have a user called jon_doe registered on Engine SaaS. This user has access to the namespace tests, and to two different instance sizes with 16GB and 32GB labelled ‘GAMS_z1d.large_A’ and ‘GAMS_z1d.xlarge_A’, respectively.
We will use the requests library and a Jupyter Notebook to explore the REST API, and submit a simple GAMS job and fetch the results.
Authentication
First we need to import the request library, and take care of authenticating our user:
import requests
from requests.auth import HTTPBasicAuth
import time
au = HTTPBasicAuth("john_doe","some_password")
url = "https://engine.gams.com/api"
You will have received your username and password in an email from our sales team after signing up for Engine Saas.
Making the First Request
We can then query the API to get information about the instances our user has access to. The results are available in json format. The value for cpu_request corresponds to the number of vCPUs available in each instance, and is slightly lower than the nominal value you will find on the AWS homepage. This is because the Engine software stack (in particular Kubernetes) requires some resources to work properly. The same is true for the memory_request values, which correspond to the available memory and also reserve a small proportion to Kubernetes. The workspace_request values show the amount of disk space (50 GB) available for each job. Finally, multiplier is the factor that determines how fast an instance type will consume the quota compared to wall time.
r = requests.get(url + '/usage/instances/john_doe', auth=au)
r.json()
{'instances_inherited_from': 'john_doe',
'default_inherited_from': 'john_doe',
'instances_available': [{'label': 'GAMS_z1d.large_A',
'cpu_request': 1.8,
'memory_request': 15070,
'workspace_request': 50000,
'node_selectors': [{'key': 'gams.com/instanceType', 'value': 'z1d.large'}],
'tolerations': [],
'multiplier': 1.0},
{'label': 'GAMS_z1d.xlarge_A',
'cpu_request': 3.8,
'memory_request': 30710,
'workspace_request': 50000,
'node_selectors': [{'key': 'gams.com/instanceType', 'value': 'z1d.xlarge'}],
'tolerations': [],
'multiplier': 1.1}],
'default_instance': {'label': 'GAMS_z1d.large_A',
'cpu_request': 1.8,
'memory_request': 15070,
'workspace_request': 50000,
'node_selectors': [{'key': 'gams.com/instanceType', 'value': 'z1d.large'}],
'tolerations': [],
'multiplier': 1.0}}
Submitting a Job
Lets move on and submit a GAMS job to Engine. We will use the trnsport model, which we have copied into the current directory, and which will need to be zipped before we can submit it. The zipped file is then used in a post request to the API. Also, we will tell Engine to use the GAMS_z1d.large_A instance type.
The response contains the job token, which we need to identify our job.
from zipfile import ZipFile
with ZipFile('model.zip','w') as zip:
zip.write('trnsport.gms')
query_params = {
'model': 'trnsport',
'namespace': 'tests',
'labels': 'instance=GAMS_z1d.large_A'
}
# Create dict with model zip file
job_files = {'model_data': open('model.zip','rb')}
r = requests.post(url + '/jobs/', params=query_params, files=job_files, auth=au)
token = r.json()['token']
When you follow along this example, please make sure to adjust the value for namespace to the one that was sent to you via email by our sales team together with your user information. If you have been invited to Engine SaaS by someone else in your organization, you will have to request this information from them.
The job runs asynchronously in the background, and we could now add more jobs or do other things.
Getting Job Results
We have to give Engine SaaS approximately 2 minutes, which is the time it takes to spin up a fresh EC2 instance for our job. This is required only for the first job in a row of successive jobs, because freshly vacated instances will be re-used and will be available immediately.
Lets now check the status of our simple job, by sending a get request.
r = requests.get(url + '/jobs/' + token, auth=au)
r.json()
{'token': '842b85cd-d7e2-42dc-8268-cc25ed3d66ce',
'model': 'trnsport',
'is_temporary_model': True,
'is_data_provided': False,
'status': 10,
'process_status': 0,
'stdout_filename': 'log_stdout.txt',
'namespace': 'tests',
'stream_entries': [],
'arguments': [],
'submitted_at': '2022-01-13T15:46:32.749866+00:00',
'finished_at': '2022-01-13T15:48:39.520392+00:00',
'user': {'username': 'john_doe', 'deleted': False, 'old_username': None},
'text_entries': [],
'dep_tokens': [],
'labels': {'cpu_request': 1.8,
'memory_request': 15070,
'workspace_request': 50000,
'tolerations': [],
'node_selectors': [{'key': 'gams.com/instanceType', 'value': 'z1d.large'}]},
'result_exists': True}
Amongst other information, we can see that the result_exists field reports True, and that
the process_status field reports a value of zero, which means the job did finish successfully. We can now download the results in the form of a zip file, by sending another get request. The content field of the return object contains the raw byte string representing the zip file, so we can just write the field to disk ‘as is’.
r = requests.get(url + '/jobs/' + token + '/result', auth=au)
file = open('results.zip','wb')
file.write(r.content)
file.close()
By default, the zip file contains the GAMS log for the run, a copy of the model file, and the lst file. Here is a section of the log that shows we did indeed successfully solve the model on GAMS Engine:
Iteration Dual Objective In Variable Out Variable
1 73.125000 x(seattle,new-york) demand(new-york) slack
2 119.025000 x(seattle,chicago) demand(chicago) slack
3 153.675000 x(san-diego,topeka) demand(topeka) slack
4 153.675000 x(san-diego,new-york) supply(seattle) slack
--- LP status (1): optimal.
--- Cplex Time: 0.11sec (det. 0.01 ticks)
Optimal solution found
Objective: 153.675000
Some Remarks on Security
Our development team takes software security serious, especially given the fact that GAMS Engine runs in the cloud. This is why we frequently update the underlying software components to include bug-fixes as soon as they come out.
Below is a high level summary of some of the design choices that will keep your data safe.
General best practices for web applications
First up, of course we make use of industry standard encryption methods. This means that all data is transported through the internet TLS encrypted. Your user credentials are stored salted and hashed in the Engine user database (we use the PBKDF2 algorithm for that). Data is AES-256 encrypted at rest in our database, and backups are encrypted as well. Before releasing any updates to GAMS Engine, the code changes are peer reviewed by our team, and additionally scanned for known vulnerabilities and tested in our CI pipeline.
Engine specific considerations
We use AWS EKS
, which is a production grade Kubernetes cluster that is professionally managed by AWS, to run our Engine infrastructure. This ensures that data from our different users is properly encapsulated, and user A cannot see under any circumstances what user B is doing. Each job that is scheduled on GAMS Engine is run in a new, isolated, containerized environment, which has never been used before to solve any model. You can however specifically instruct Engine to make job B dependent on job A, in which case the data from job A will be accessible to job B.
On top of that, our namespace structure allows you to choose who can access which model, and what they can do with the model. We follow the standard permission system present on unix operating systems (read, write, execute).
With Quotas, you can limit usage of individual users in your organization to prevent people from burning through your compute volume too quickly. Quotas can be set for the number of simultaneous jobs started, for the number of hours available to a user, for the types of instances a user is allowed to use, and also for the amount of storage available.
If this overview has piqued your interest, do not hesitate to contact us. We are happy to discuss your requirements and give you more information in a personal call.