Table of Contents
Concept
GAMS Connect is a framework inspired by the concept of a so-called ETL (extract, transform, load) procedure that allows to integrate data from various data sources. The GAMS Connect framework consists of the Connect database and the Connect agents that operate on the Connect database. Via the available Connect interfaces the user passes instructions to call Connect agents for reading data from various file types into the Connect database, transforming data in the Connect database, and writing data from the Connect database to various file types. Instructions are passed in YAML syntax. Note that in contrast to a typical ETL procedure, read, transform and write operations do not need to be strictly separated.
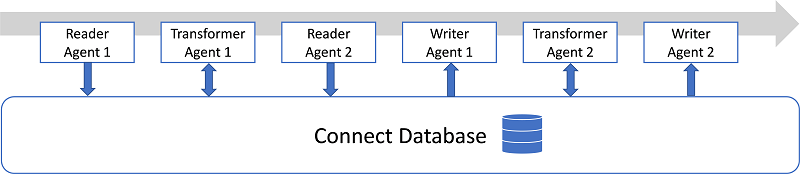
Usage
GAMS Connect is available via the GAMS command line parameters ConnectIn and ConnectOut, via embedded code Connect, and as a standalone command line utility gamsconnect.
Instructions processed by the GAMS Connect interfaces need to be passed in YAML syntax as follows:
- <agent name1>:
<root option1>: <value>
<root option2>: <value>
.
.
<root option3>:
- <option1>: <value>
<option2>: <value>
.
.
- <option1>: <value>
<option2>: <value>
.
.
.
.
- <agent name2>:
.
.
.
.
The user lists the instructions to be performed. All individual agent instructions begin at the same indentation level starting with a - (a dash and a space) followed by the Connect agent name and a : (a colon). Connect agent options are represented in a simple <option>: <value> form. Please check the documentation of Connect Agents for available options. Options at the first indentation level are called root options and typically define general settings, e.g. the file name. While some agents only have root options, others have a more complex options structure, where a root option may be a list of dictionaries containing other options. A common example is the root option symbols (see e.g. GDXReader). Via symbols many agents allow to define symbol specific options, e.g. the name of the symbol. The option tables of agents with a more complex options structure provide a Scope to reflect this structure - options may be allowed at the first indentation level (root) and/or are assigned to other root options (e.g. symbols).
Checkout the GAMS Studio Connect Editor that allows creating and editing YAML instructions by a simple drag and drop of agents and corresponding options.
Note that YAML syntax also supports an abbreviated form for lists and dictionary, e.g. <root option3>: [ {<option1>: <value>, <option2>: <value>}, {<option1>: <value>, <option2>: <value>} ].
Here is an example that uses embedded Connect code to process instructions:
$onecho > distance.csv
i;j;distance in miles
seattle;new-york;2,5
seattle;chicago;1,7
seattle;topeka;1,8
san-diego;new-york;2,5
san-diego;chicago;1,8
san-diego;topeka;1,4
$offecho
$onecho > capacity.csv
i,capacity in cases
seattle,350.0
san-diego,600.0
$offecho
Set i 'Suppliers', j 'Markets';
Parameter d(i<,j<) 'Distance', a(i) 'Capacity';
$onEmbeddedCode Connect:
- CSVReader:
file: distance.csv
name: distance
indexColumns: [1, 2]
valueColumns: [3]
fieldSeparator: ';'
decimalSeparator: ','
- CSVReader:
file: capacity.csv
name: capacity
indexColumns: [1]
valueColumns: [2]
- GAMSWriter:
symbols:
- name: distance
newName: d
- name: capacity
newName: a
$offEmbeddedCode
display i, j, d, a;
In this example, we are reading two CSV files distance.csv and capacity.csv using the CSVReader. Then we directly write to symbols in GAMS using the GAMSWriter.
Initialization and Execution Phase
The Connect database processes instructions in two phases: The initialization phase and the execution phase. During the initialization phase, the Connect database sequentially instantiates the specified agents and validates the agent instructions, i.e. validates the specified agent options. If all agents passed the initialization phase, the Connect database continues with the execution phase. In this step, the agent instructions are executed. If an error occurs during initialization or execution of agent instructions, subsequent agents are not further processed and the Connect database immediately returns the error.
GAMS Studio Connect Editor
The GAMS Studio Connect Editor provides functionalities for creating and editing so-called GAMS Connect files, containing instructions in YAML syntax which will be processed by the GAMS Connect interfaces. With the Connect Editor, the user can create YAML instructions by a simple drag and drop of agents and corresponding options, instead of creating the YAML instructions for Connect manually. The content of the Connect file can also be displayed and edited in plain YAML format using a text editor. See documentation of the Connect Editor for more information.
Connect Agents Overview
Current Connect agents support the following data source formats: CSV, Excel, GDX and SQL. The following Connect agents are available:
| Connect agent | Description | Supported symbol types |
|---|---|---|
| Concatenate | Allows concatenating multiple symbols in the Connect database. | Sets and parameters |
| CSVReader | Allows reading a symbol from a specified CSV file into the Connect database. | Sets and parameters |
| CSVWriter | Allows writing a symbol in the Connect database to a specified CSV file. | Sets and parameters |
| DomainWriter | Allows rewriting the domain information of an existing Connect symbol. | Sets, parameters, variables, and equations |
| ExcelReader | Allows reading symbols from a specified Excel file into the Connect database. | Sets and parameters |
| ExcelWriter | Allows writing symbols in the Connect database to a specified Excel file. | Sets and parameters |
| Filter | Allows to reduce symbol data by applying filters on labels and numerical values. | Sets, parameters, variables, and equations |
| GAMSReader | Allows reading symbols from the GAMS database into the Connect database. | Sets, parameters, variables, and equations |
| GAMSWriter | Allows writing symbols in the Connect database to the GAMS database. | Sets, parameters, variables, and equations |
| GDXReader | Allows reading symbols from a specified GDX file into the Connect database. | Sets, parameters, variables, and equations |
| GDXWriter | Allows writing symbols in the Connect database to a specified GDX file. | Sets, parameters, variables, and equations |
| LabelManipulator | Allows to modify labels of symbols in the Connect database. | Sets, parameters, variables, and equations |
| Projection | Allows index reordering, projection onto a reduced index space, and expansion to an extended index space through index duplication of a GAMS symbol. | Sets, parameters, variables, and equations |
| PythonCode | Allows executing arbitrary Python code. | - |
| RawCSVReader | Allows reading unstructured data from a specified CSV file into the Connect database. | - |
| RawExcelReader | Allows reading unstructured data from a specified Excel file into the Connect database. | - |
| SQLReader | Allows reading symbols from a specified SQL database into the Connect database. | Sets and parameters |
| SQLWriter | Allows writing symbols in the Connect database to a specified SQL database. | Sets and parameters |
Getting Started Examples
We introduce the basic functionalities of GAMS Connect agents on some simple examples. For more examples see section Examples.
CSV
The following example (a modified version of the trnsport model) shows how to read and write CSV files. The full example is part of DataLib as model connect03. Here is a code snippet of the first lines:
$onEcho > distance.csv
i,new-york,chicago,topeka
seattle,2.5,1.7,1.8
san-diego,2.5,1.8,1.4
$offEcho
$onEcho > capacity.csv
i,capacity
seattle,350
san-diego,600
$offEcho
$onEcho > demand.csv
j,demand
new-york,325
chicago,300
topeka,275
$offEcho
Set i 'canning plants', j 'markets';
Parameter d(i<,j<) 'distance in thousands of miles'
a(i) 'capacity of plant i in cases'
b(j) 'demand at market j in cases';
$onEmbeddedCode Connect:
- CSVReader:
file: distance.csv
name: d
indexColumns: 1
valueColumns: "2:lastCol"
- CSVReader:
file: capacity.csv
name: a
indexColumns: 1
valueColumns: 2
- CSVReader:
file: demand.csv
name: b
indexColumns: 1
valueColumns: 2
- GAMSWriter:
symbols: all
$offEmbeddedCode
[...]
It starts out with the declaration of sets and parameters. With compile-time embedded Connect code, data for the parameters is read from CSV files using the Connect agent CSVReader. The CSVReader agent, for example, reads the CSV file distance.csv and creates the parameter d in the Connect database. The name of the parameter must be given by the option name. Column number 1 is specified as the first domain set using option indexColumns. The valueColumns option is used to specify the column numbers 2, 3 and 4 containing the values. Per default, the first row of the columns specified via valueColumns will be used as the second domain set. The symbolic constant lastCol can be used if the number of index or value columns is unknown. As a last step, all symbols from the Connect database are written to the GAMS database using the Connect agent GAMSWriter. The GAMSWriter agent makes the parameters d, a and b available outside the embedded Connect code. Note that the sets i and j are defined implicitly through parameter d.
Finally, after solving the transport model, Connect can be used to export results to a CSV file:
[...]
Model transport / all /;
solve transport using lp minimizing z;
embeddedCode Connect:
- GAMSReader:
symbols:
- name: x
- Projection:
name: x.l(i,j)
newName: x_level(i,j)
- CSVWriter:
file: shipment_quantities.csv
name: x_level
unstack: True
endEmbeddedCode
This time, we need to use execution-time embedded Connect code. The Connect agent GAMSReader imports variable x into the Connect database. With the Connect agent CSVWriter we write the variable level to the CSV file shipment_quantities.csv:
i_0,new-york,chicago,topeka seattle,50.0,300.0,0.0 san-diego,275.0,0.0,275.0
Setting the option unstack to True allows to use the last dimension as the header row.
Excel
The following example is part of GAMS Model Library as model cta and shows how to read and write Excel spreadsheets. Here is a code snippet of the first lines:
Set
i 'rows'
j 'columns'
k 'planes';
Parameter
dat(k<,i<,j<) 'unprotected data table'
pro(k,i,j) 'information sensitive cells';
* extract data from Excel workbook
$onEmbeddedCode Connect:
- ExcelReader:
file: cox3.xlsx
symbols:
- name: dat
range: Sheet1!A1
rowDimension: 2
columnDimension: 1
- name: pro
range: Sheet2!A1
rowDimension: 2
columnDimension: 1
- GAMSWriter:
symbols: all
$offEmbeddedCode
[...]
It starts out with the declaration of sets and parameters. With compile-time embedded Connect code, data for the parameters is read from the Excel file cox3.xlsx using the Connect agent ExcelReader. The ExcelReader agent allows reading data for multiple symbols that are listed under the keyword symbols, here, parameter dat and pro. For each symbol, the symbol name is given by option name and the Excel range by option range. The option rowDimension defines that the first two columns of the data range will be used for the labels. In addition, the option columnDimension defines that the first row of the data range will be used for the labels. As a last step, all symbols from the Connect database are written to the GAMS database using the Connect agent GAMSWriter. The GAMSWriter agent makes the parameters dat and pro available outside the embedded Connect code. Note that the sets i, j and k are defined implicitly through parameter dat.
Finally, after solving the cox3c model with alternative solutions, Connect can be used to export results to Excel:
[...]
loop(l$((obj.l - best)/best <= 0.01),
ll(l) = yes;
binrep(s,l) = round(b.l(s));
binrep('','','Obj',l) = obj.l;
binrep('','','mSec',l) = cox3c.resUsd*1000;
binrep('','','nodes',l) = cox3c.nodUsd;
binrep('Comp','Cells','Adjusted',l) = sum((i,j,k)$(not s(i,j,k)), 1$round(adjn.l(i,j,k) + adjp.l(i,j,k)));
solve cox3c min obj using mip;
);
embeddedCode Connect:
- GAMSReader:
symbols:
- name: binrep
- ExcelWriter:
file: results.xlsx
clearSheet: True
symbols:
- name: binrep
endEmbeddedCode
This time, we need to use execution-time embedded Connect code. The Connect agent GAMSReader imports the reporting parameter binrep into the Connect database. With the Connect agent ExcelWriter we write the parameter into the binrep sheet of the Excel file results.xlsx.
SQL
The following example (a modified version of the whouse model) shows how to read from and write to a SQL database (sqlite). The full example is part of DataLib as model connect04. Here is a code snippet of the first lines:
[...]
Set t 'time in quarters';
Parameter
price(t) 'selling price ($ per unit)'
istock(t) 'initial stock (units)';
Scalar
storecost 'storage cost ($ per quarter per unit)'
storecap 'stocking capacity of warehouse (units)';
$onEmbeddedCode Connect:
- SQLReader:
connection: {"database": "whouse.db"}
symbols:
- name: t
query: "SELECT * FROM timeTable;"
type: set
- name: price
query: "SELECT * FROM priceTable;"
- name: istock
query: "SELECT * FROM iniStockTable;"
- name: storecost
query: "SELECT * FROM storeCostTable;"
- name: storecap
query: "SELECT * FROM storeCapTable;"
- GAMSWriter:
symbols: all
$offEmbeddedCode
[...]
It starts out with the declaration of sets and parameters. With compile-time embedded Connect code, data for all the symbols are read from the sqlite database whouse.db using the Connect agent SQLReader by passing the connection url through the option connection. The SQLReader agent, for example, queries the table priceTable for data and creates the parameter price in the Connect database. The SQLReader allows reading data for multiple symbols that are listed under the keyword symbols and are fetched through the same connection. For each symbol the name must be given by the option name. The SQL query statement is passed through the option query. The symbol type can be specified using the option type. By default, every symbol is treated as a GAMS parameter. As a last step, all symbols from the Connect database are written to the GAMS database using the Connect agent GAMSWriter. The GAMSWriter agent makes all read in symbols available outside the embedded Connect code.
Further, after solving the warehouse model, Connect can be used to export the results to tables in the SQL database.
[...]
Model swp 'simple warehouse problem' / all /;
solve swp minimizing cost using lp;
embeddedCode Connect:
- GAMSReader:
symbols: all
- Projection:
name: stock.l(t)
newName: stock_level(t)
- Projection:
name: sell.l(t)
newName: sell_level(t)
- Projection:
name: buy.l(t)
newName: buy_level(t)
- SQLWriter:
connection: {"database": "whouse.db"}
ifExists: replace
symbols:
- name: stock_level
tableName: stock_level
- name: sell_level
tableName: sell_level
- name: buy_level
tableName: buy_level
endEmbeddedCode
Here, we need to use execution-time embedded Connect code. The Connect agent GAMSReader imports all the variables into the Connect database. The SQLWriter agent then writes each symbol to respective tables in the SQL database whouse.db. For example the stock level:
|t_0 |level | |:-------|:---------| |q-1 |100.0 | |q-2 |0.0 | |q-3 |0.0 | |q-4 |0.0 |
The ifExists option allows to either append to an extending table or replace it with new data. By default, the value for ifExists is set to fails.
Connect Agents
This section provides a reference for the available Connect agents and their options. Each agent provides a table overview of available options that allows to identify the scope of an option as well as its default value.
Each option can be either optional or required:
- If an optional option is omitted, it will automatically receive a default value.
- Required options must be provided, but only if the parent option has been specified. A typical example is the
symbolsoption. By default,symbolsis set toallfor certain agents. However, ifsymbolsis specified as a list of individual symbols (instead ofall), then its child optionnamebecomes required.
- Note
- The option value
nullindicates that an option is missing. For optional options, it is allowed to setnullwhich will have the same effect as omitting the option. This means that even an explicitnullwill result in the default value for this option.
The table overview also allows to determine the scope of an option. In some cases, agents may have the same option available across different scopes, for example the root scope and the symbols scope:
- An omitted option in the
symbolsscope inherits its value from therootscope. Therefore, the technical default of the option in thesymbolsscope isnullwhich indicates that the option is omitted and inherits the value from therootscope. Note that the table overview does not show this technicalnulldefault. - If an option is specified in the
symbolsscope, it will not inherit the value from therootscope.
Concatenate
The Concatenate agent allows concatenating multiple input symbols (sets or parameters) in the Connect database into a single output symbol of the same type. It takes the union of domain sets of all input symbols and uses that as the domain for the output symbol. There are several options to guide this domain finding process which are explained below. The general idea is best explained with an example. Consider three parameters p1(i,j), p2(k,i), and p3(k,l). The union of all domain sets is i, j, k, and l and, hence, the output symbol will be parameterOutput(symbols,i,j,k,l). The very first index of parameterOutput contains the name of the input symbol followed by the domain sets. If a domain set is not used by a specific input symbol the corresponding records in parameterOutput will feature the emptyUel, a - (dash) by default, as the following figures show:
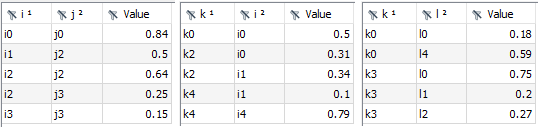
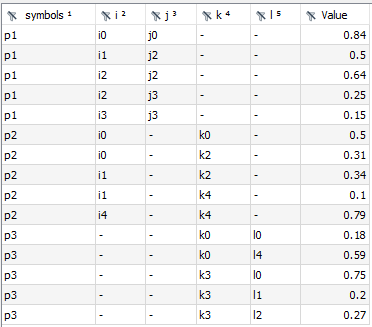
The Concatenate agent is especially useful in combination with UI components that provide a pivot table, like GAMS MIRO, to represent many individual output symbols in a single powerful and configurable table format.
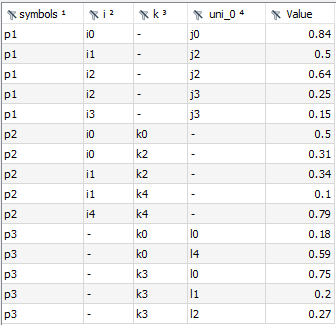
Obviously, there are more complex situations with respect to the domain of the resulting parameterOutput. For example, only a subset of domain sets are relevant and the remaining ones should be combined in as few index positions as possible. For this, assume only domain sets i and k from the above example are relevant and j and l can be combined in a single index position - a so-called universal domain. The resulting parameterOutput would look as follows:
Moreover, the Concatenate agent needs to deal with universe domain sets * and domain sets that are used multiple times in an input symbol. In addition to the symbols index (always the first index position of the output symbol), by default the union of domain sets of the input symbols determine the domain of the output symbol. If a domain set (including the universe *) appears multiple times in an input symbol's domain, these duplicates will be part of the output symbol's domain. For example, q1(*,i,j,*) and q2(*,i,i) will result in the output symbol parameterOutput(symbols,*,i,j,*,i,) by default, mapping index positions 1 to 4 of q1 to positions 2 to 5 of parameterOutput and index positions 1 to 3 of q2 to 2, 3, and 6.
All the described situations can be configured with a few options of the agent. The option outputDimensions allows to control the domain of the output symbol. The default behavior (outputDimension: all) gets the domain sets from the input symbols and builds the union with duplicates if required. Alternatively, outputDimensions can be a list of the relevant domain sets (including an empty list). In any case, the agent iterates through the input symbols and maps the index positions of each input symbol into the index positions of the output symbol using the domain set names. Names not present in the list of outputDimensions will be added as universal domains. Per default, the domain set names of an input symbol will be the original domain set names as stored in the Connect database. There are two ways to adjust the domain set names of input symbols: dimensionMap and an explicitly given domain for a symbol in the name option. The dimensionMap which is given once and holds for all symbols allows to map original domain names of input symbols to the desired domain names. The name option provides such a map by symbol and via the index position rather than the domain names of the input symbol. In the above example with p1(i,j), p2(k,i), and p3(k,l), we could put indices i and l as well as j and k together resulting in the following output symbol:
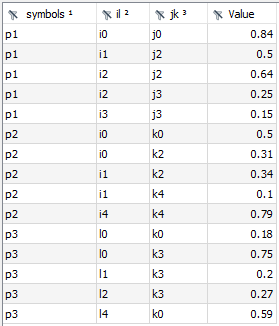
This can be accomplished in two ways: either we use dimensionMap: {i: il, l: il, j: jk, k: jk} or we use name: p1(il,jk), name: p2(jk,il), and name: p3(jk,il) to explicitly define the domain names for each symbol. Note that it is not required to set outputDimensions: [il,jk] since per default the union of domain sets is built using the mapped domain names. In case a domain set is used more than once in a domain of an input symbol the mapping goes from left to right to find the corresponding output domain. If this is not desired, the Projection agent can be used to reorder index positions in symbols or explicit index naming can be used. In the example with q1(*,i,j,*) and q2(*,i,i), the second index position of q2 will be put together with the second index position of q1. If one wants to map the second i of q2 (in the third index position) together with the i of q1 (in second index position), one can, e.g. do with name: q1(*,i,j,*), and name: q2(*,i2,i).
- Note
- The Concatenate agent creates result symbols
parameterOutputandsetOutputfor parameters and sets separately. Both have the same output domain. If different output domains forparameterOutputandsetOutputare desired, use two instantiations of the Concatenate agent. - Variables and equations need to be turned into parameters with the Projection agent before they can be concatenated.
- If option
nameis given without an explicit domain for the input symbol, the domain names stored in the Connect container are used and mapped via thedimensionMapoption, if provided. - A domain set of an input symbol that cannot be assigned to an index in
outputDimensionswill be mapped to a so-called universal domain. The Concatenate agent automatically adds as many universal domains as required to the output symbols.
- The Concatenate agent creates result symbols
Here is an example that uses the Concatenate agent:
Sets
i(i) / i0*i3 "i_text" /
j(j) / j0*j3 "j_text" /
k(k) / k0*k3 "k_text" /;
Parameters
p1(i) / i1 1 /
p2(k,j) / k1.j0 2, k1.j1 3, k1.j3 4 /
p3(j,j) / j1.j2 5, j2.j0 6, j3.j1 7, j3.j2 8 /
s / 5 /;
Positive Variable x(i,j);
x.l(i,j)$(uniform(0,1)>0.8) = uniformint(0,10);
embeddedCode Connect:
- GAMSReader:
symbols: all
- Projection:
name: x.l(i,j)
newName: x_level(i,j)
- Concatenate:
outputDimensions: [j,i]
- GDXWriter:
file: concat_output.gdx
symbols:
- name: setOutput
- name: parameterOutput
endEmbeddedCode
The resulting set and parameter outputs look as follows:
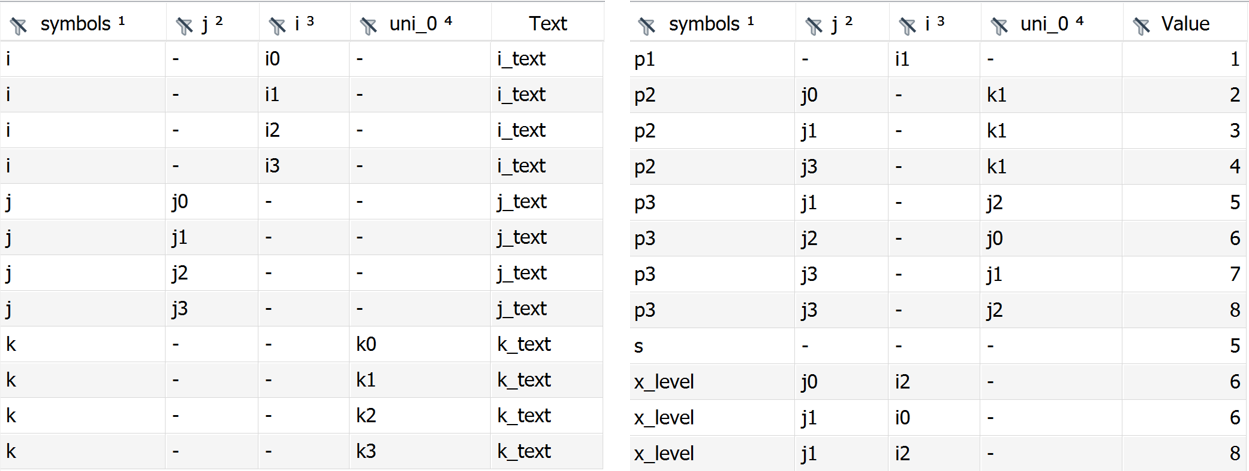
The following options are available for the Concatenate agent.
| Option | Scope | Default | Description |
|---|---|---|---|
| dimensionMap | root | null | Define a mapping for the domain names of input symbols as stored in the Connect database to the desired domain names. |
| emptyUel | root | - | Define a character to use for empty UELs. |
| name | symbols | Specify the name of the symbol with potentially index space. | |
| newName | symbols | null | Specify a new name for the symbol in the symbols dimension of the output symbol. |
| outputDimensions | root | all | Define the dimensions of the output symbols. |
| parameterName | root | parameterOutput | Name of the parameter output symbol. |
| setName | root | setOutput | Name of the set output symbol. |
| skip | root | null | Indicate if sets or parameters should be skipped. |
| symbols | root | all | Specify symbol specific options. |
| symbolsDimension | root | True | Specify if output symbols should have a symbols dimension. |
| trace | root | 0 | Specify the trace level for debugging output. |
| universalDimension | root | uni | Specify the base name of universal dimensions. |
Detailed description of the options:
dimensionMap: dictionary (default: null)
Define a mapping for domain names of input symbols as stored in the Connect database to the desired domain names. For example,
dimensionMap: {i: ij, j: ij}will map both symbol domainsiandjtoij.
Define a character to use for empty UELs.
Specify the name of the symbol with potentially index space. Requires the format
symName(i1,i2,...,iN). The index space may be specified to establish a mapping for the domain names of the symbol as stored in the Connect database to the desired domain names. If no index space is provided, the domain names stored in the Connect data are used and mapped via thedimensionMapoption if provided.
newName: string (default: null)
Specify a new name for the symbol in the
symbolsdimension of the output symbol.
outputDimensions: all, list of strings (default: all)
Allows to control the dimensions of the output symbols. The default behavior (
outputDimension: all) gets the domain sets from the input symbols and builds the union with duplicates if required. Alternatively,outputDimensionscan be a list of the relevant domain sets (including an empty list), e.g.outputDimensions: [i,j]. In any case, the agent iterates through the input symbols and maps the index positions of each input symbol into the index positions of the output symbol using the domain set names. Names not present in the list ofoutputDimensionswill be added as universal dimensions. If the domain set names of input symbols in the Connect database are not suitable, there are two ways to define different domain set names: dimensionMap and an explicitly given domain for a symbol in the name option.
parameterName: string (default: parameterOutput)
Name of the parameter output symbol.
setName: string (default: setOutput)
Name of the set output symbol.
skip: set, par (default: null)
Indicate if sets or parameters should be skipped. Per default the agent takes both sets and parameters into account (if both are available via symbols) and generates a set and parameter output symbol with the same domain. If
setis specified, the sets will be skipped, i.e. sets are not taken into account for setting up the domain and no set output symbol will be generated. Ifparis specified, the parameters will be skipped.
symbols: all, list of symbols (default: all)
A list containing symbol specific options. Allows to concatenate a subset of symbols. The default
allconcatenates all sets and parameters in the given database.
symbolsDimension: boolean (default: True)
Specify if output symbols should have a
symbolsdimension that contains the input symbol names. IfTrue, the Concatenate agent adds asymbolsdimension at the first index position. IfFalse, nosymbolsdimension will be added.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
universalDimension: string (default: uni)
Specify the base name of universal dimensions.
CSVReader
The CSVReader allows reading a symbol (set or parameter) from a specified CSV file into the Connect database. Its implementation is based on the pandas.DataFrame class and its I/O API method read_csv. See getting started example for a simple example that uses the CSVReader.
| Option | Default | Description |
|---|---|---|
| autoColumn | null | Generate automatic column names. |
| autoRow | null | Generate automatic row labels. |
| decimalSeparator | . (period) | Specify a decimal separator. |
| fieldSeparator | , (comma) | Specify a field separator. |
| file | Specify a CSV file path. | |
| header | infer | Specify the header(s) used as the column names. |
| indexColumns | null | Specify columns to use as the row labels. |
| indexSubstitutions | null | Dictionary used for substitutions in the index columns. |
| name | Specify a symbol name for the Connect database. | |
| names | null | List of column names to use. |
| quoting | 0 | Control field quoting behavior. |
| readCSVArguments | null | Dictionary containing keyword arguments for the pandas.read_csv method. |
| skipRows | null | Specify the rows to skip or the number of rows to skip. |
| stack | infer | Stacks the column names to index. |
| thousandsSeparator | null | Specify a thousands separator. |
| trace | 0 | Specify the trace level for debugging output. |
| type | par | Control the symbol type. |
| valueColumns | null | Specify columns to get the values from. |
| valueSubstitutions | null | Dictionary used for substitutions in the value columns. |
Detailed description of the options:
autoColumn: string (default: null)
Generate automatic column names. The
autoColumnstring is used as the prefix for the column label numbers. This option overrides the use of aheaderornames. However, if there is a header row, one must skip the row by enablingheaderor usingskipRows.
autoRow: string (default: null)
Generate automatic row labels. The
autoRowstring is used as the prefix for the row label numbers. The generated unique elements will be used in the first index position shifting other elements to the right. UsingautoRowcan be helpful when there are no labels that can be used as unique elements but also to store entries that would be a duplicate entry without a unique row label.
decimalSeparator: string (default: .)
Specify a decimal separator, e.g.
.(period) or,(comma).
fieldSeparator: string (default: ,)
Specify a field separator, e.g.
,(comma),;(semicolon), or\t(tab).
- Attention
- When specifying escape sequences like tabs (
\t) or newlines (\n), you must enclose the value in double quotes (e.g.fieldSeparator: "\t"). Standard YAML parsing treats single quotes ('\t') or unquoted strings (\t) as literal two-character strings (a backslash followed by a letter). Because the underlying reader interprets separators longer than one character as a regular expression, using single quotes or unquoted strings will trigger a ParserWarning and force a fallback to a slower parsing engine.
Specify a CSV file path.
header: infer, boolean, list of integers (default: infer)
Specify the header(s) used as the column names. Default behavior is to infer the column names: if no names are passed the behavior is identical to
header=Trueand column names are inferred from the first line of data, if column names are passed explicitly then the behavior is identical toheader=False. Explicitly passheader=Trueto be able to replace existing names. Note that missing column names are filled withUnnamed: n(where n is the nth column (zero based) in theDataFrame). Hence, reading the CSV file:,j1, i1,1,2 i2,3,4 ,5,6results in the following 2-dimensional parameter:
j1 Unnamed: 2 i1 1.000 2.000 i2 3.000 4.000For a multi-row header, a list of integers can be passed providing the positions of the header rows in the data. Note that reading multi-row header is only supported for parameters. Moreover, the CSVReader can only read all columns and not a subset of columns, wherefore only
indexColumnscan be specified and all other columns will automatically be read asvalueColumns. Note thatindexColumnscan not be provided as column names together with a multi-row header.autoRowandautoColumnwill be ignored in case of a multi-row header. Here is an example how to read data with a multi-row header:$onecho > multirow_header.csv j,,j1,j1,j1,j2,j2,j2 k,,k1,k2,k3,k1,k2,k3 h,i,,,,,, h1,i1,1,2,,4,5,6 h1,i2,,,3,4,5, $offEcho $onEmbeddedCode Connect: - CSVReader: file: multirow_header.csv name: p header: [1,2] indexColumns: [1,2] - PythonCode: code: | print(connect.container["p"].records) $offEmbeddedCodeThe same can be achieved if the data has no index column names:
j,,j1,j1,j1,j2,j2,j2 k,,k1,k2,k3,k1,k2,k3 h1,i1,1,2,,4,5,6 h1,i2,,,3,4,5,If the first line of data after the multi-row header has no data in the
valueColumns, the CSVReader will interpret this line as index column names.
indexColumns: integer, string, list of integers, list of strings (default: null)
Specify columns to use as the row labels. The columns can either be given as column positions or column names. Column positions can be represented as an integer, a list of integers or a string. For example:
indexColumns: 1,indexColumns: [1, 2, 3, 4, 6]orindexColumns: "1:4, 6". The symbolic constantlastColcan be used with the string representation:"2:lastCol". If noheaderornamesis provided,lastColwill be determined by the first line of data. Column names can be represented as a list of strings. For example:indexColumns: ["i1","i2"]. Note thatindexColumnsandvalueColumnsmust either be given as positions or names not both. Further note thatindexColumnsas column names are not supported together with a multi-row header.By default the
pandas.read_csvmethod interprets the following indices asNaN: "", "#N/A", "#N/A N/A", "#NA", "-1.#IND", "-1.#QNAN", "-NaN", "-nan", "1.#IND", "1.#QNAN", "<NA>", "N/A", "NA", "NULL", "NaN", "n/a", "nan", "null". The default can be changed by specifyingpandas.read_csvargumentskeep_default_naandna_valuesvia readCSVArguments. Rows with indices that are interpreted asNaNwill be dropped automatically. The indexSubstitutions option allows to mapNaNentries in the index columns.
indexSubstitutions: dictionary (default: null)
Dictionary used for substitutions in the index columns. Each key in
indexSubstitutionsis replaced by its corresponding value. This option allows arbitrary replacements in the index columns of theDataFrameincluding stacked column names. Consider the following CSV file:i1,j1,2.5 i1,,1.7 i2,j1,1.8 i2,,1.4Reading this data into a 2-dimensional parameter results in a parameter with
NaNentries dropped:j1 i1 2.500 i2 1.800By specifying
indexSubstitutions: { .nan: j2 }we can substituteNaNentries byj2:j1 j2 i1 2.500 1.700 i2 1.800 1.400
Specify a symbol name for the Connect database. Note that each symbol in the Connect database must have a unique name.
names: list of strings (default: null)
List of column names to use. If the file contains a header row, then you should explicitly pass
header=Trueto override the column names. Duplicates in this list are not allowed.
quoting: 0, 1, 2, 3 (default: 0)
Control field quoting behavior. Use QUOTE_MINIMAL (
0), QUOTE_ALL (1), QUOTE_NONNUMERIC (2) or QUOTE_NONE (3). QUOTE_NONNUMERIC (2) instructs the reader to convert all non-quoted fields to type float. QUOTE_NONE (3) instructs reader to perform no special processing of quote characters.
readCSVArguments: dictionary (default: null)
Dictionary containing keyword arguments for the pandas.read_csv method. Not all arguments of that method are exposed through the YAML interface of the CSVReader agent. By specifying
readCSVArguments, it is possible to pass arguments directly to thepandas.read_csvmethod that is used by the CSVReader agent. For example,readCSVArguments: {encoding_errors: 'replace', keep_default_na: False}.Potentially useful arguments could be:
encoding_errors: How encoding errors are treated (default:'strict').keep_default_na: Whether or not to include the defaultNaNvalues when parsing the data (default:True). By default the following values are interpreted asNaN: empty string, "NaN", "N/A", "NULL", and other common representations of missing data.na_values: Additional strings to recognize asNaN.on_bad_lines: Specifies what to do upon encountering a bad line (a line with too many fields) (default:'error').skip_blank_lines: IfTrue, skip over blank lines rather than interpreting asNaNvalues (default:True).See pandas.read_csv documentation for more details.
skipRows: integer, list of integers (default: null)
Specify the rows to skip (list) or the number of rows to skip (integer). For example:
skipRows: [1, 3]orskipRows: 5.
stack: infer, boolean (default: infer)
If
True, stacks the column names to index. With the defaultinfer,stackwill be set toTrueif there is more than one value column, otherwiseFalse. Note that missing column names are filled withUnnamed: n(where n is the nth column (zero based) in theDataFrame).
thousandsSeparator: string (default: null)
Specify a thousands separator.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
Control the symbol type. Supported symbol types are
parfor parameters andsetfor sets.
valueColumns: integer, string, list of integers, list or strings (default: null)
Specify columns to get the values from. The value columns contain numerical values in case of a GAMS parameter and set element text in case of a GAMS set. Note that specifying
valueColumnsis required for parameters (except for parameter data with a multi-row header). The columns can be given as column positions or column names. Column positions can be represented as an integer, a list of integers or a string. For example:valueColumns: 1,valueColumns: [1, 2, 3, 4, 6]orvalueColumns: "1:4, 6". The symbolic constantlastColcan be used with the string representation:"2:lastCol". If noheaderornamesis provided,lastColwill be determined by the first line of data. Column names can be represented as a list of strings. For example:valueColumns: ["i1","i2"]. Note thatvalueColumnsandindexColumnsmust either be given as positions or names not both.By default the
pandas.read_csvmethod interprets the following values asNaN: "", "#N/A", "#N/A N/A", "#NA", "-1.#IND", "-1.#QNAN", "-NaN", "-nan", "1.#IND", "1.#QNAN", "<NA>", "N/A", "NA", "NULL", "NaN", "n/a", "nan", "null". The default can be changed by specifyingpandas.read_csvargumentskeep_default_naandna_valuesvia readCSVArguments. Rows with values that are interpreted asNaNwill be dropped automatically. Changing the default of values that are interpreted asNaNis useful if, e.g. "NA" values should not be dropped but interpreted as GAMS special valueNA. Moreover, the valueSubstitutions option allows to mapNaNentries in the value columns.
valueSubstitutions: dictionary (default: null)
Dictionary used for substitutions in the value column. Each key in
valueSubstitutionsis replaced by its corresponding value. The replacement is only performed on the values which is the numerical value in case of a GAMS parameter and the set element text in case of a GAMS set. While it is possible to make arbitrary replacements this is especially useful for controlling sparse/dense reading. AllNaNentries are removed automatically by default which results in a sparse reading behavior. Consider the following CSV file:i1,j1, i1,j2,1.7 i2,j1, i2,j2,1.4Reading this data into a 2-dimensional parameter results in a sparse parameter with all
NaNentries removed:j2 i1 1.700 i2 1.400By specifying
valueSubstitutions: { .nan: EPS }we get a dense representation where allNaNentries are replaced by GAMS special valueEPS:j1 j2 i1 EPS 1.700 i2 EPS 1.400Beside
EPSthere are the following other GAMS special values that can be used by specifying their string representation:INF,-INF,EPS,NA, andUNDEF. See the GAMS Transfer documentation for more information.Let's assume we have data representing a GAMS set:
i1,text1 i2, i3,text3Reading this data into a 1-dimensional set results in a sparse set in which all
NaNentries (those that do not have any set element text) are removed:'i1' 'text 1', 'i3' 'text 3'By specifying
valueSubstitutions: { .nan: '' }we get a dense representation:'i1' 'text 1', 'i2', 'i3' 'text 3'It is also possible to use
valueSubstitutionsin order to interpret the set element text. Let's assume we have the following CSV file:,j1,j2,j3 i1,Y,Y,Y i2,Y,Y,N i3,0,Y,YReading this data into a 2-dimensional set results in a dense set:
'i1'.'j1' Y, 'i1'.'j2' Y, 'i1'.'j3' Y, 'i2'.'j1' Y, 'i2'.'j2' Y, 'i2'.'j3' N, 'i3'.'j1' 0, 'i3'.'j2' Y, 'i3'.'j3' YBy specifying
valueSubstitutions: { 'N': .nan, '0': .nan }we replace all occurrences ofNand0byNaNwhich gets dropped automatically:'i1'.'j1' Y, 'i1'.'j2' Y, 'i1'.'j3' Y, 'i2'.'j1' Y, 'i2'.'j2' Y, 'i3'.'j2' Y, 'i3'.'j3' Y
CSVWriter
The CSVWriter allows writing a symbol (set or parameter) in the Connect database to a specified CSV file. Variables and equations need to be turned into parameters with the Projection agent before they can be written. See getting started example for a simple example that uses the CSVWriter.
| Option | Default | Description |
|---|---|---|
| decimalSeparator | . (period) | Specify a decimal separator. |
| file | Specify a CSV file path. | |
| fieldSeparator | , (comma) | Specify a field separator. |
| header | True | Indicate if the header will be written. |
| name | Specify the name of the symbol in the Connect database. | |
| quoting | 0 | Control field quoting behavior. |
| setHeader | null | Specify a string that will be used as the header. |
| skipText | False | Indicate if the set element text will be skipped. |
| toCSVArguments | null | Dictionary containing keyword arguments for the pandas.to_csv method. |
| trace | 0 | Specify the trace level for debugging output. |
| unstack | False | Specify the dimensions to be unstacked to the header row(s). |
| valueSubstitutions | null | Dictionary used for mapping in the value column of the DataFrame. |
Detailed description of the options:
decimalSeparator: string (default: .)
Specify a decimal separator, e.g.
.(period) or,(comma).
- Note
- Changing the decimal separator (e.g. to
,) will have no effect if the value column contains non-numerical values. This can be the case if either numerical values are replaced with strings using valueSubstitutions or in case of special values which get translated into strings by default.
Specify a CSV file path.
fieldSeparator: string (default: ,)
Specify a field separator, e.g.
,(comma),;(semicolon), or\t(tab).
- Attention
- When specifying escape sequences like tabs (
\t) or newlines (\n), you must enclose the value in double quotes (e.g.fieldSeparator: "\t"). Standard YAML parsing treats single quotes ('\t') or unquoted strings (\t) as literal two-character strings (a backslash followed by a letter). Because the underlying reader interprets separators longer than one character as a regular expression, using single quotes or unquoted strings will trigger a ParserWarning and force a fallback to a slower parsing engine.
header: boolean (default: True)
Indicate if the header will be written.
Specify the name of the symbol in the Connect database.
quoting: 0, 1, 2, 3 (default: 0)
Control field quoting behavior. Use QUOTE_MINIMAL (
0), QUOTE_ALL (1), QUOTE_NONNUMERIC (2) or QUOTE_NONE (3). QUOTE_MINIMAL (0) instructs the writer to only quote those fields which contain special characters such asfieldSeparator. QUOTE_ALL (1) instructs the writer to quote all fields. QUOTE_NONNUMERIC (2) instructs the writer to quote all non-numeric fields. QUOTE_NONE (3) instructs the writer to never quote fields.
setHeader: string (default: null)
Specify a string that will be used as the header. If an empty header is desired, the string can be empty.
skipText: boolean (default: False)
Indicate if the set element text will be skipped. If
False, the set element text will be written in the last column of the CSV file.
toCSVArguments: dictionary (default: null)
Dictionary containing keyword arguments for the pandas.to_csv method. Not all arguments of that method are exposed through the YAML interface of the CSVWriter agent. By specifying
toCSVArguments, it is possible to pass arguments directly to thepandas.to_csvmethod that is used by the CSVWriter agent. For example,toCSVArguments: {index_label: ["index1", "index2", "index3"]}.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
unstack: boolean, list of integers (default: False)
Specify the dimensions to be unstacked to the header row(s). If
False(default) no dimension will be unstacked to the header row. IfTruethe last dimension will be unstacked to the header row. If multiple dimensions should be unstacked to header rows, a list of integers providing the dimension numbers to unstack can be specified.
valueSubstitutions: dictionary (default: null)
Dictionary used for mapping in the value column of the
DataFrame. Each key invalueSubstitutionsis replaced by its corresponding value. The replacement is only performed on the value column of theDataFramewhich is the numerical value in case of a GAMS parameter and the set element text in case of a GAMS set. Note that for parameters the CSVWriter automatically converts numerical GAMS special values to their string representation, i.e.INF,-INF,EPS,NA, andUNDEF. If the GAMS special values should be replaced by custom values, use the string representation (upper case) in the dictionary. For example, specify{'EPS': 0}to replace GAMS special valueEPSby zero. See the GAMS Transfer documentation for more information on GAMS special values.
DomainWriter
The DomainWriter agent allows to rewrite domain information for existing Connect symbols and helps dealing with domain violations.
Here is an example that uses the DomainWriter agent:
Set i / i1*i2 /, ii(i) / i1 /;
Parameter a(i) / i1 1, i2 2 /, b(i) / i1 1, i2 2 /;
$onEmbeddedCode Connect:
- GAMSReader:
symbols: all
- DomainWriter:
symbols:
- name: a(ii)
dropDomainViolations: after
- name: b('ii')
- PythonCode:
code: |
print("Parameter a:\n", connect.container["a"].records)
print("Parameter b:\n",connect.container["b"].records)
- GDXWriter:
file: a_mod.gdx
symbols: all
$offEmbeddedCode
In this example, the DomainWriter is used to modify the one-dimensional parameters a and b. For parameter a, a regular domain with domain set ii (a subset of set i) is established. Since parameter a still has the (i2 2.0) record, the parameter now contains a domain violation as i2 is not part of the new regular domain ii. While the Connect database in general can hold symbols with domain violations, this is not the case for GAMS or GDX. Since the symbols are later written to GDX, dropDomainViolations: after is specified instructing the DomainWriter to drop all domain violations after the new domain is applied. For parameter b, a relaxed domain 'ii' is established. This means that the universal domain * is established while using ii as the relaxed domain name. As the new domain is relaxed, no domain violations are introduced.
After the DomainWriter parameter a and b look as follows:
Set a:
ii value
0 i1 1.0
Set b:
ii value
0 i1 1.0
1 i2 2.0
| Option | Scope | Default | Description |
|---|---|---|---|
| dropDomainViolations | root/symbols | False | Indicate how to deal with domain violations. |
| name | symbols | Specify the name of the symbol in the Connect database. | |
| symbols | root | all | Specify symbol specific options. |
| trace | root | 0 | Specify the trace level for debugging output. |
Detailed description of the options:
dropDomainViolations: after, before, boolean (default: False)
The Connect symbols might have some domain violations. This agent allows to drop these domain violations, so a write to GAMS or GDX works properly. Indicate how to deal with domain violations that can cause issues in GAMS or GDX. Per default domain violations will not be dropped. Setting
dropDomainViolationstoafterwill drop domain violations after a new domain is applied. Setting the option tobeforewill drop domain violations before a new domain is applied. Setting the option toTruewill drop domain violations before and after a new domain is applied. The DomainWriter agent does not necessarily need to be used to rewrite domain information for specific symbols but can also handle domain violations for all symbols in the Connect database. Withsymbols: allanddropDomainViolations: Truethe agent drops domain violations from all symbols in the Connect database. In this case,afterandbeforewill have the same effect asTrue.
Specify a symbol name with index space for the Connect database.
namerequires the formatsymName(i1,i2,...,iN). The list of indices needs to coincide with the names of the actual GAMS domain sets for a regular domain. A relaxed domain is set if the index is quoted. For examplename: x(i,'j')means that for the first index a regular domain with domain setiis established, while for the second index the universal domain*is used and a relaxed domain namejis set.
symbols: all, list of symbols (default: all)
A list containing symbol specific options or
allfor applying the DomainWriter to all symbols in the Connect database.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
ExcelReader
The ExcelReader agent allows to read symbols (sets and parameters) from an Excel file into the Connect database. See getting started example for a simple example that uses the ExcelReader.
- Note
- The ExcelReader supports
.xlsxand.xlsmfiles..xlsbfiles are supported on Windows only and require an Excel installation.
| Option | Scope | Default | Description |
|---|---|---|---|
| autoMerge | root/symbols | False | Indicate if empty cells in the labels should be merged with previous cells. |
| columnDimension | root/symbols | 1 | Column dimension of the symbol. |
| file | root | Specify an Excel file path. | |
| ignoreColumns | symbols | null | Columns to be ignored when reading. |
| ignoreRows | symbols | null | Rows to be ignored when reading. |
| ignoreText | root/symbols | infer | Indicate if the set element text should be ignored. |
| index | root | Specify the Excel range for reading symbols and options directly from the spreadsheet. | |
| indexSubstitutions | root/symbols | null | Dictionary used for substitutions in the row and column index. |
| mergedCells | root/symbols | False | Control the handling of empty cells in the labels and the values that are part of a merged Excel range. |
| name | symbols | Specify the name of the symbol in the Connect database. | |
| range | symbols | [name]!A1 | Specify the Excel range of a symbol. |
| rowDimension | root/symbols | 1 | Row dimension of the symbol. |
| skipEmpty | root/symbols | 1 | Number of empty rows or columns to skip before the next empty row or column indicates the end of the block for reading with open ranges. |
| symbols | root | Specify symbol specific options. | |
| trace | root | 0 | Specify the trace level for debugging output. |
| type | root/symbols | par | Control the symbol type. |
| valueSubstitutions | root/symbols | null | Dictionary used for mapping in the values. |
Detailed description of the options: autoMerge: boolean (default: False)
Indicate if empty cells in the labels should be merged with previous cells. If
True, each empty cell in the labels will be filled with the value of a previous cell that is not empty. This will resolve merged cells in the labels and will also fill empty cells in the labels that are not part of a merged cell. If the user wants to keep empty cells in the labels that are not part of a merged cell and still resolve merged cells,autoMergeneeds to be set toFalseand mergedCells needs to be set toTrue.
columnDimension: integer (default: 1)
The number of rows in the data range that will be used to define the labels for columns. The first
columnDimensionrows of the data range will be used for labels.
Specify an Excel file path.
ignoreColumns: integer, string, list of integers and strings (default: null)
Columns to be ignored when reading the file. They can be specified by any of the following methods:
- Single column: Use a single column number (e.g.
ignoreColumns: 3) or letter (e.g.ignoreColumns: C).- Ranges: Specify ranges in the format
start:end. Ranges can include:
- Integers (e.g.
ignoreColumns: "2:6")- Letters (e.g.
ignoreColumns: "B:F")- A mixture of both (e.g.
ignoreColumns: "B:6")- A list of columns: Include multiple column numbers, letters, and/or ranges (e.g.
ignoreColumns: [2, "D", "7:10"]).
ignoreRows: integer, string, list of integers and strings> (default: null)
Specify rows to be ignored when reading. You can specify:
- Single row: Use a single row number (e.g.
ignoreRows: 4).- Ranges: Specify ranges in the format
start:end. Ranges should only include integers (e.g.ignoreRows: "2:6").- A list of rows: Include multiple row numbers and/or ranges (e.g.
ignoreRows: [2, 5, "7:10"].)
ignoreText: infer, boolean (default: infer)
Indicate if the set element text should be ignored. With the default
inferthe set element text will be ignored based on the specification of range and columnDimension/rowDimension. If eithercolumnDimensionorrowDimensionis set to0and an open range is specified, the set element text will be ignored. If eithercolumnDimensionorrowDimensionis set to0and a full range is specified, the set element text will be ignored if it is not included in the range specification. In all other cases the set element text will not be ignored.
index: string (required: index or symbols) (excludes: symbols)
Specify the Excel range for reading symbols options directly from the spreadsheet similar to GDXXRWs index option. The general structure of an index sheet follows roughly the rules of
GDXXRW, but there are also options that are either not supported at all or work differently.
- Supported options:
rdim/rowDimensioncdim/columnDimensionse/skipEmptyignoreTextautoMergeignoreRowsignoreColumnsmergedCells- All supported options are processed case insensitive.
- All unsupported options are ignored.
- Since there is no support for
dSet, the ExcelReader will process such symbols asset. The duplicateRecords option of the GAMSWriter or GDXWriter can be used to get rid of potential duplicate records. Alternatively the Projection agent with an appropriate aggregationMethod can be used.- No support for
dimbutrDim/rowDimensionandcDim/columnDimensiononly.- Missing values for
rDim/rowDimensionandcDim/columnDimensionwill not have theGDXXRWdefaults but will use the root-scoped values of rowDimension and columnDimension. When migrating fromGDXXRWto Connect it is best to explicitly specify those values in the index sheet instead of relying on default value.- Per default
GDXXRWdoes not store zeros, but the ExcelReader does. In order to change this, one has to specifyvalueSubstitutions: {0: .nan}in the root scope which will drop all records with value0.This option can not be specified together with symbols.
indexSubstitutions: dictionary (default: null)
Dictionary used for substitutions in the row and column index. Each key in
indexSubstitutionsis replaced by its corresponding value. This option allows arbitrary replacements in the index. Consider the following Excel spreadsheet: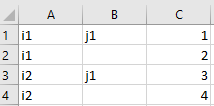 Two dimensional data containing NaN entries in the index
Two dimensional data containing NaN entries in the indexReading this data into a 2-dimensional parameter results in a parameter with
NaNentries dropped:j1 i1 1.000 i2 3.000By specifying
indexSubstitutions: { .nan: j2 }we can substituteNaNentries byj2:j1 j2 i1 1.000 2.000 i2 3.000 4.000
mergedCells: boolean (default: False)
Control the handling of empty cells that are part of a merged Excel range. The option applies to merged cells in the labels and the values, i.e. the numerical values in case of a GAMS parameter and the set element text in case of a GAMS set. If
False, the cells are left empty. IfTrue, the merged label/value is used in all cells. Note that setting this option toTruehas an impact on performance since the Excel file has to be opened in a non-read-only mode that results in non-constant memory consumption (no lazy loading). From the performance perspective, autoMerge should be preferred overmergedCellsif applicable.
Specify a symbol name for the Connect database. Note that each symbol in the Connect database must have a unique name.
range: string (default: [name]!A1)
Specify the Excel range of a symbol using the format
sheetName!cellRange.cellRangecan be either a single cell also known as an open range (north-west corner likeB2) or a full range (north-west and south-east corner likeB2:D4). Per default the ExcelReader uses the range[name]!A1, where[name]is the name of the symbol that is read. If onlysheetName!is specified, the ExcelReader will use an open range starting at cellA1. The ExcelReader also allows for named ranges - a named range includes a sheet name and a cell range. Before interpreting the providedrangeattribute, the string will be used to search for a pre-defined Excel range with that name.
rowDimension: integer (default: 1)
The number of columns in the data range that will be used to define the labels for the rows. The first
rowDimensioncolumns of the data range will be used for the labels.
skipEmpty: integer (default: 1)
Number of empty rows or columns to skip before the next empty row or column indicates the end of the block for reading with open ranges. If a full range is specified
skipEmptywill be ignored.
symbols: list of symbols (required: index or symbols) (excludes: index)
A list containing symbol specific options.
This option can not be specified together with index.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
Control the symbol type. Supported symbol types are
parfor parameters andsetfor sets.
valueSubstitutions: dictionary (default: null)
Dictionary used for substitutions in the value column. Each key in
valueSubstitutionsis replaced by its corresponding value. The replacement is only performed on the values which is the numerical value in case of a GAMS parameter and the set element text in case of a GAMS set. While it is possible to make arbitrary replacements, this is especially useful for controlling sparse/dense reading. AllNaNentries are removed automatically by default which results in a sparse reading behavior. Let's assume we have the following spreadsheet: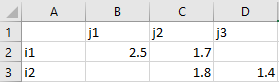 Two dimensional data containing NaN entries
Two dimensional data containing NaN entriesReading this data into a 2-dimensional parameter results in a sparse parameter in which all
NaNentries are removed:'i1'.'j1' 2.5, 'i1'.'j2' 1.7, 'i2'.'j2' 1.8, 'i2'.'j3' 1.4By specifying
valueSubstitutions: { .nan: EPS }we get a dense representation in which allNaNentries are replaced by GAMS special valueEPS:'i1'.'j1' 2.5, 'i1'.'j2' 1.7, 'i1'.'j3' Eps, 'i2'.'j1' Eps, 'i2'.'j2' 1.8, 'i2'.'j3' 1.4Beside
EPSthere are the following other GAMS special values that can be used by specifying their string representation:INF,-INF,EPS,NA, andUNDEF. See the GAMS Transfer documentation for more information.Let's assume we have data representing a GAMS set:
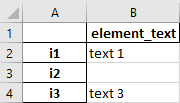 Data representing a GAMS set
Data representing a GAMS setReading this data into a 1-dimensional set results in a sparse set in which all
NaNentries (those that do not have any set element text) are removed:'i1' 'text 1', 'i3' 'text 3'By specifying
valueSubstitutions: { .nan: '' }we get a dense representation:'i1' 'text 1' 'i2' '' 'i3' 'text 3'It is also possible to use
valueSubstitutionsin order to interpret the set element text. Let's assume we have the following Excel data: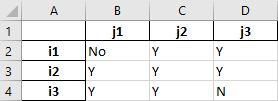 Data representing a GAMS set
Data representing a GAMS setReading this data into a 2-dimensional set results in a dense set:
'i1'.'j1' No, 'i1'.'j2' Y, 'i1'.'j3' Y, 'i2'.'j1' Y, 'i2'.'j2' Y, 'i2'.'j3' Y, 'i3'.'j1' Y, 'i3'.'j2' Y, 'i3'.'j3' NBy specifying
valueSubstitutions: { 'N': .nan, 'No': .nan }we replace all occurrences ofNandNobyNaNwhich gets dropped automatically. Note thatNohas to be quotes in order to not be interpreted asFalseby the YAML parser:'i1'.'j2' Y, 'i1'.'j3' Y, 'i2'.'j1' Y, 'i2'.'j2' Y, 'i2'.'j3' Y, 'i3'.'j1' Y, 'i3'.'j2' Y
ExcelWriter
The ExcelWriter agent allows to write symbols (sets and parameters) from the Connect database to an Excel file. Variables and equations need to be turned into parameters with the Projection agent before they can be written. If the Excel file exists, the ExcelWriter appends to the existing file. See getting started example for a simple example that uses the ExcelWriter.
- Note
- The ExcelWriter only supports
.xlsxfiles.
- Attention
- Please be aware of the following limitation when appending to an Excel file with formulas using the ExcelWriter: Whereas Excel stores formulas and the corresponding values, the ExcelReader and the ExcelWriter read/store either formulas or values, not both. As a consequence, when appending to an Excel file with formulas, all cells with formulas within the Excel file will not have values anymore and a subsequent read by the ExcelReader results into
NaNfor these cells. To avoid this, write to a separate output Excel file. On Windows one can merge the input Excel file with the output Excel file at the end using the tool win32.ExcelMerge (see Connect Example for Excel (executeTool win32.ExcelMerge)). An alternative approach when appending to an Excel file with formulas is to open and save the Excel file before reading it to let Excel evaluate formulas and restore the corresponding values.
| Option | Scope | Default | Description |
|---|---|---|---|
| clearSheet | root/symbols | False | Indicate if a sheet should be cleared before writing if it exists. |
| columnDimension | root/symbols | infer | Column dimension of the symbol. |
| file | root | Specify an Excel file path. | |
| index | root | null | Specify the Excel range for reading symbols and options directly from the spreadsheet. |
| mergedCells | root/symbols | False | Write merged cells. |
| name | symbols | Specify the name of the symbol in the Connect database. | |
| range | symbols | [name]!A1 | Specify the Excel range of a symbol. |
| sheetName | tableOfContents | Table Of Contents | Specify the sheet name containing the table of contents. |
| skipText | root/symbols | False | Indicate if the set element text will be skipped. |
| sort | tableOfContents | False | Controls if symbol names in the table of contents are sorted alphabetically. |
| symbols | root | all | Specify symbol specific options. |
| tableOfContents | root | False | Controls the writing of a table of contents. |
| trace | root | 0 | Specify the trace level for debugging output. |
| valueSubstitutions | root/symbols | null | Dictionary used for mapping in the value column of the DataFrame. |
Detailed description of the options:
clearSheet: boolean, range (default: False)
Indicate if a sheet should be cleared before writing. The default is
Falsewhere a sheet will not be cleared, instead the ExcelWriter overwrites, i.e. writes content to the sheet without removing the existing content. IfTruewas specified, all cells of the sheet will be cleared before writing. Ifrangewas specified, the range from the range option is used for determining the cells to be cleared. A single cell (north-west corner likeB2) clears all data from that point extending to the bottom-right of the sheet. A full range (north-west and south-east corner likeB2:D4) clears only the content inside that specific block.
columnDimension: infer, integer (default: infer)
The last
columnDimensionindex positions of the symbol that will be written to the rows that define the labels of the columns. The firstdim-columnDimensionindex positions will be written to the columns that define the labels for the rows. With the defaultinfer,columnDimensionwill be set to1ifdim>0and otherwise to0.
Specify an Excel file path.
Specify the Excel range for reading symbols options directly from the spreadsheet similar to GDXXRWs index option. If specified, symbols is ignored. The general structure of an index sheet follows roughly the rules of
GDXXRW, but there are also options that are either not supported at all or work differently.
- Supported options:
cdim/columnDimensionmergedCellsclearSheet- All supported options are processed case insensitive.
- All unsupported options are ignored.
- No support for
dimbut andrDim/rowDimensionbutcDim/columnDimensiononly.- Missing value for
cDim/columnDimensionwill use the root-scoped value of columnDimension. When migrating fromGDXXRWto Connect it is best to explicitly specify this value in the index sheet instead of relying on the default value.
mergedCells: boolean (default: False)
Write merged cells. Please be aware that overwriting already existing merged cells in a sheet may cause problems, in that case consider setting clearSheet to
True.
Specify a symbol name for the Connect database.
range: string (default: [name]!A1)
Specify the Excel range of a symbol using the format
sheetName!cellRange.cellRangecan be either a single cell (north-west corner likeB2) or a full range (north-west and south-east corner likeB2:D4). Per default the ExcelWriter uses the range[name]!A1, where[name]is the name of the symbol that is written. For symbol names exceeding 31 characters, a truncated sheet name will be used. If onlysheetName!is specified, the ExcelWriter will use an open range starting at cellA1. The ExcelWriter also allows for named ranges - a named range includes a sheet name and a cell range. Before interpreting the providedrangeattribute, the string will be used to search for a pre-defined Excel range with that name.
sheetName: string (default: Table Of Contents)
Specify the sheet name which will contain the table of contents.
skipText: boolean (default: False)
Indicate if the set element text will be skipped. If
False, set element text will be written.
sort: boolean (default: False)
If
Truethe table of contents is sorted by symbol name in alphabetical order. IfFalsethe order is determined from the order given in symbols or the order of symbols in the Connect database in casesymbols: all.
symbols: all, list of symbols (default: all)
A list containing symbol specific options. The default
allwrites each parameter and set into a separate sheet using the range[name]!A1. If specified, index takes precedence oversymbols.
tableOfContents: boolean, dictionary (default: False)
If
Truewrites a table of contents into sheetTable Of Contents. If a dictionary is provided, valid keys are sheetName and sort. The sheet used for the table of contents is always cleared before writing.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
valueSubstitutions: dictionary (default: null)
Dictionary used for mapping in the value column of the
DataFrame. Each key invalueSubstitutionsis replaced by its corresponding value. The replacement is only performed on the value column of theDataFramewhich is the numerical value in case of a GAMS parameter and the set element text in case of a GAMS set. Note that for parameters the ExcelWriter automatically converts numerical GAMS special values to their string representation, i.e.INF,-INF,EPS,NA, andUNDEF. If the GAMS special values should be replaced by custom values, use the string representation (upper case) in the dictionary. For example, specify{'EPS': 0}to replace GAMS special valueEPSby zero. See the GAMS Transfer documentation for more information on GAMS special values.
Filter
The Filter agent allows to reduce symbol data by applying filters on labels and numerical values. Here is an example that uses the Filter agent:
Set i / seattle, san-diego /
j / new-york, chicago, topeka /;
Parameter d(i,j) /
seattle.new-york 2.5
seattle.chicago 1.7
seattle.topeka 1.8
san-diego.new-york 2.5
san-diego.chicago 1.8
san-diego.topeka 1.4
/;
$onEmbeddedCode Connect:
- GAMSReader:
symbols:
- name: d
- Filter:
name: d
newName: d_new
labelFilters:
- dimension: 1
keep: ['seattle']
- dimension: 2
reject: ['topeka']
valueFilters:
- rule: x<2.5
- GDXWriter:
file: report.gdx
symbols:
- name: d_new
$offEmbeddedCode
The records of the parameter d are filtered and stored in a new parameter called d_new. Two label filters remove all labels except seattle from the first dimension and remove the label topeka from the second one. The remaining records are filtered by value where only values less than 2.5 are kept in the data. The resulting parameter d_new which is exported into report.gdx has only one record (seattle.chicago 1.7) left.
The following options are available for the Filter agent:
| Option | Scope | Default | Description |
|---|---|---|---|
| attribute | valueFilters | all | Specify the attribute to which a value filter is applied. |
| dimension | labelFilters | all | Specify the dimension to which a label filter is applied. |
| keep | labelFilters | Specify a list of labels to keep. | |
| labelFilters | root | null | Specify filters for index columns of a symbol. |
| name | root | Specify a symbol name for the Connect database. | |
| newName | root | null | Specify a new name for the symbol in the Connect database. |
| regex | labelFilters | Specify a regular expression to be used for filtering labels. | |
| reject | labelFilters | Specify a list of labels to reject. | |
| rejectSpecialValues | valueFilters | null | Specify the special values to reject. |
| rule | valueFilters | null | Specify a boolean expression to be used for filtering on numerical columns. |
| ruleIdentifier | valueFilters | x | The identifier used for the value filter rule. |
| trace | root | 0 | Specify the trace level for debugging output. |
| valueFilters | root | null | Specify filters for numerical columns of a symbol. |
Detailed description of the options:
attribute: all, value, level, marginal, upper, lower, scale (default: all)
Used to specify the attribute to which a value filter is applied. The following strings are allowed depending on the symbol type:
- Set: Not allowed
- Parameter:
all(default),value- Variable and equation:
all(default),level,marginal,upper,lower,scaleThe default
allwill apply the value filter on all value columns of the symbol.
dimension: all, integer (default: all)
Used to specify the dimension to which a label filter is applied. The default
allwill apply the label filter on all dimensions of the symbol.
keep: list of strings (required: keep or regex or reject) (excludes: regex, reject)
A list of labels to be kept when applying the label filter.
This option can not be specified together with regex or reject.
labelFilters: list of label filters (default: null)
A list containing label filters.
Specify the name of the symbol from the Connect database on whose data the filters will be applied.
newName: string (default: null)
Specify a new name for the symbol in the Connect database which will get the data after all filters have been applied. Each symbol in the Connect database must have a unique name.
regex: string (required: keep or regex or reject) (excludes: keep, reject)
A string containing a regular expression that needs to match in order to keep the corresponding label. Uses a full match paradigm which means that the whole label needs to match the specified regular expression.
This option can not be specified together with keep or reject.
reject: string (required: keep or regex or reject) (excludes: keep, regex)
A list of labels to be rejected when applying the label filter.
This option can not be specified together with keep or regex.
rejectSpecialValues: EPS, +INF, -INF, UNDEF, NA, list of special values (default: null)
Can be used to reject single special values, e.g.
rejectSpecialValues: EPS, or a list of special values, e.g.rejectSpecialValues: [EPS, UNDEF, -INF]. The following string representation of the GAMS special values must be used:INF,-INF,EPS,NAandUNDEF.
Used to specify a boolean expression for a value filter. Each numerical value of the specified dimension is tested and the corresponding record is only kept if the expression evaluates to true. The string needs to contain Python syntax that is valid for
pandas.Series. Comparison operators like>,>=,<,<=,==, or!=can be used in combination with boolean operators like&or|, but notandoror. Note that using&or|requires the operands to be enclosed in round brackets in order to form a valid expression. As an example, the expression((x<=10) & (x>=0)) | (x>20)would keep only those values that are between0and10(included) or greater than20.
ruleIdentifier: string (default: x)
Specifies the identifier that is used in the rule of a value filter.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
valueFilters: list of value filters (default: null)
A list containing value filters.
GAMSReader
The GAMSReader allows reading symbols from the GAMS database into the Connect database. Without GAMS context (e.g. when running the gamsconnect script from the command line) this agent is not available and its execution will result in an exception.
The GAMSReader allows to either read all symbols from the GAMS database:
- GAMSReader:
symbols: all
Or specific symbols only:
- GAMSReader:
symbols:
- name: i
- name: p
newName: p_new
| Option | Scope | Default | Description |
|---|---|---|---|
| name | symbols | Specify the name of the symbol in the GAMS database. | |
| newName | symbols | null | Specify a new name for the symbol in the Connect database. |
| symbols | root | all | Specify symbol specific options. |
| trace | root | 0 | Specify the trace level for debugging output. |
Detailed description of the options:
Specify the name of the symbol in the GAMS database.
newName: string (default: null)
Specify a new name for the symbol in the Connect database. Each symbol in the Connect database must have a unique name.
symbols: all, list of symbols (default: all)
A list containing symbol specific options. Allows to read a subset of symbols. The default
allreads all symbols from the GAMS database into the Connect database.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
GAMSWriter
The GAMSWriter allows writing symbols in the Connect database to the GAMS database. Without GAMS context (e.g. when running the gamsconnect script from the command line) and as part of the connectOut command line option this agent is not available and its execution will result in an exception.
The GAMSWriter allows to either write all symbols in the Connect database to the GAMS database:
- GAMSWriter:
symbols: all
Or specific symbols only:
- GAMSWriter:
symbols:
- name: i
- name: p
newName: p_new
| Option | Scope | Default | Description |
|---|---|---|---|
| domainCheckType | root/symbols | default | Specify if domain checking is applied or if records that would cause a domain violation are filtered. |
| duplicateRecords | root/symbols | all | Specify which record(s) to keep in case of duplicate records. |
| mergeType | root/symbols | default | Specify if data in a GAMS symbol is merged or replaced. |
| name | symbols | Specify the name of the symbol in the Connect database. | |
| newName | symbols | null | Specify a new name for the symbol in the GAMS database. |
| symbols | root | all | Specify symbol specific options. |
| trace | root | 0 | Specify the trace level for debugging output. |
Detailed description of the options:
domainCheckType: checked, default, filtered (default: default)
Specify if Domain Checking is applied (
checked) or if records that would cause a domain violation are filtered (filtered). If left atdefaultit depends on the setting of $on/offFiltered if GAMS does a filtered load or checks the domains during compile time. During execution timedefaultis the same asfiltered.
duplicateRecords: all, first, last, none (default: all)
A symbol in the Connect database can hold multiple records for the same indexes. Such duplicate records are only a problem when exchanging the data with GAMS (and GDX). The attribute determines which record(s) to keep in case of (case insensitive) duplicate records. With the default of
allthe GAMSWriter will fail in case duplicate records exist. Withfirstthe first record will be written to GAMS, withlastthe last record will be written to GAMS. Withnonenone of the duplicate records will be written to GAMS. Note that the agent deals with duplicate records in a case insensitive way.
mergeType: default, merge, replace (default: default)
Specify if data in a GAMS symbol is merged (
merge) or replaced (replace). If left atdefaultit depends on the setting of $on/offMulti[R] if GAMS does a merge, replace, or triggers an error during compile time. During execution timedefaultis the same asmerge.
Specify the name of the symbol in the Connect database.
newName: string (default: null)
Specify a new name for the symbol in the GAMS database. Note, each symbol in the GAMS database must have a unique name.
symbols: all, list of symbols (default: all)
A list containing symbol specific options. Allows to write a subset of symbols. The default
allwrites all symbols from the Connect database into the GAMS database. Symbols that do not exist in the GAMS database are skipped. Symbols that exist but have different symbol types in the Connect and GAMS database will raise an error.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
GDXReader
The GDXReader allows reading symbols from a specified GDX file into the Connect database.
The GDXReader allows to either read all symbols from a GDX file:
- GDXReader:
file: in.gdx
symbols: all
Or specific symbols only:
- GDXReader:
file: in.gdx
symbols:
- name: i
- name: p
newName: p_new
| Option | Scope | Default | Description |
|---|---|---|---|
| file | root | Specify a GDX file path. | |
| name | symbols | Specify the name of the symbol in the GDX file. | |
| newName | symbols | null | Specify a new name for the symbol in the Connect database. |
| symbols | root | all | Specify symbol specific options. |
| trace | root | 0 | Specify the trace level for debugging output. |
Detailed description of the options:
Specify a GDX file path.
Specify the name of the symbol in the GDX file.
newName: string (default: null)
Specify a new name for the symbol in the Connect database. Each symbol in the Connect database must have a unique name.
symbols: all, list of symbols (default: all)
A list containing symbol specific options. Allows to read a subset of symbols. The default
allreads all symbols from the GDX file into the Connect database.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
GDXWriter
The GDXWriter allows writing symbols in the Connect database to a specified GDX file.
The GDXWriter allows to either write all symbols in the Connect database to a GDX file:
- GDXWriter:
file: out.gdx
symbols: all
Or specific symbols only:
- GDXWriter:
file: out.gdx
symbols:
- name: i
- name: p
newName: p_new
| Option | Scope | Default | Description |
|---|---|---|---|
| duplicateRecords | root/symbols | all | Specify which record(s) to keep in case of duplicate records. |
| file | root | Specify a GDX file path. | |
| name | symbols | Specify the name of the symbol in the Connect database. | |
| newName | symbols | null | Specify a new name for the symbol in the GDX file. |
| symbols | root | all | Specify symbol specific options. |
| trace | root | 0 | Specify the trace level for debugging output. |
Detailed description of the options:
duplicateRecords: all, first, last, none (default: all)
A symbol in the Connect database can hold multiple records for the same indexes. Such duplicate records are only a problem when exchanging the data with GDX (and GAMS). The attribute determines which record(s) to keep in case of (case insensitive) duplicate records. With the default of
allthe GDXWriter will fail in case duplicate records exist. Withfirstthe first record will be written to GDX, withlastthe last record will be written to GDX. Withnonenone of the duplicate records will be written to GDX. Note that the agent deals with duplicate records in a case insensitive way.
Specify a GDX file path.
Specify the name of the symbol in the Connect database.
newName: string (default: null)
Specify a new name for the symbol in the GDX file. Note, each symbol in the GDX file must have a unique name.
symbols: all, list of symbols (default: all)
A list containing symbol specific options. Allows to write a subset of symbols. The default
allwrites all symbols from the Connect database into to the GDX file.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
LabelManipulator
The LabelManipulator agent allows to modify labels of symbols in the Connect database. Four different modes are available:
- case: Applies either upper, lower, or capitalize casing to labels.
- code: Replaces labels using a Python code.
- map: Uses a 1-dimensional GAMS set to perform an explicit mapping of labels.
- regex: Performs a replacement based on a regular expression.
The LabelManipulator supports manipulating the labels of the entire symbol (default) or in a specific dimension by specifying the dimension option.
Here is an example that uses the LabelManipulator agent in all four modes:
Set i / seattle, san-diego /
j / new-york, chicago, topeka /
map / chicago 'Berlin', san-diego 'Oslo' /;
Parameter d(i,j) /
seattle.new-york 2.5
seattle.chicago 1.7
seattle.topeka 1.8
san-diego.new-york 2.5
san-diego.chicago 1.8
san-diego.topeka 1.4
/;
$onEmbeddedCode Connect:
- GAMSReader:
symbols: all
- LabelManipulator:
map:
setName: map
- LabelManipulator:
case:
rule: upper
- LabelManipulator:
symbols:
- name: d
code:
rule: x.split('-')[-1]
- LabelManipulator:
symbols:
- name: d
regex:
pattern: '[^O]$'
replace: '\g<0>X'
dimension: 1
- PythonCode:
code: |
print("Set i:\n", connect.container["i"].records)
print("Set j:\n",connect.container["j"].records)
print("Parameter d:\n",connect.container["d"].records)
$offEmbeddedCode
In this example, various LabelManipulator agents are utilized to demonstrate different label manipulation capabilities:
- The first LabelManipulator uses the
mapmode to apply mappings defined in the GAMS setmapacross all symbols in the Connect database. Specifically, it maps the labelchicagotoBerlinandsan-diegotoOslo, affecting all occurrences of these labels. - The second LabelManipulator employs the
casemode to convert all symbol labels in the database to uppercase. This modification is applied universally to every label across all symbols. - The third LabelManipulator, configured in
codemode, targets only the symbold. It processes each label by splitting it at the hyphen (-) and retains only the last segment of the split. For instance, the labelNEW-YORKis transformed toYORK. - The last LabelManipulator, operating in
regexmode and equipped with thedimensionoption set to 1, specifically alters labels in the first dimension of the symbold(i.e. theidimension ind(i,j)). It appends anXto labels in the first dimension that do not end with anO.
The resulting symbols look as follows:
Set i:
uni element_text
0 SEATTLE
1 OSLO
Set j:
uni element_text
0 NEW-YORK
1 BERLIN
2 TOPEKA
Parameter d:
i j value
0 SEATTLEX YORK 2.5
1 SEATTLEX BERLIN 1.7
2 SEATTLEX TOPEKA 1.8
3 OSLO YORK 2.5
4 OSLO BERLIN 1.8
5 OSLO TOPEKA 1.4
The following options are available for the LabelManipulator agent:
| Option | Scope | Default | Description |
|---|---|---|---|
| case | root | Apply specified casing to labels. | |
| code | root | Replace labels using Python code. | |
| dimension | root/symbols | all | Specify the dimension of the symbols for label manipulations. |
| invert | map | False | Used to invert the mapping direction. |
| map | root | Replace labels using a 1-dimensional GAMS set containing an explicit key-value mapping. | |
| name | symbols | Specify a symbol name for the Connect database. | |
| newName | symbols | null | Specify a new name for the symbol in the Connect database. |
| outputSet | regex/case/code | null | Name of the output set that contains the applied mapping. |
| pattern | regex | The regular expression that needs to match. | |
| regex | root | Replace labels using a regular expression. | |
| replace | regex | The rule used for replacing labels that match the given pattern. | |
| rule | case/code | case: The type of casing to be applied. code: Python function that defines the mapping behavior. | |
| ruleIdentifier | code | x | The identifier used for labels in the rule. |
| setName | map | The name of the GAMS set used in map mode. | |
| symbols | root | all | Specify symbol specific options. |
| trace | root | 0 | Specify the trace level for debugging output. |
Detailed description of the options:
case: dictionary (required: case or code or map or regex) (excludes: code, map, regex)
Used for executing the LabelManipulator in case mode to apply a specified casing to labels.
This option can not be specified together with code, map, or regex.
code: dictionary (required: case or code or map or regex) (excludes: case, map, regex)
Used for executing the LabelManipulator in code mode to replace labels using a Python function. The given Python function is executed with each label and its return value is used as the replacement.
This option can not be specified together with case, map, or regex.
dimension: all, integer, list of integers (default: all)
Specifies the dimension(s) of the symbol that the label manipulations will be applied to. The default
allwill apply manipulations to all dimensions of the symbol.
invert: boolean (default: False)
Used for controlling the mapping direction in map mode. If set to
False(default), the labels that match a label of the provided 1-dimensional GAMS set are replaced by the corresponding set element text. If set toTruethe direction is inverted, meaning all labels that match a set element text of the GAMS set are replaced by the corresponding label.
map: dictionary (required: case or code or map or regex) (excludes: case, code, regex)
Used for executing the LabelManipulator in map mode to replace labels using a 1-dimensional GAMS set containing an explicit key-value mapping.
This option can not be specified together with case, code, or regex.
Specify the name of the symbol in the GAMS database. Data of the symbol gets replaced if no newName is specified.
newName: string (default: null)
Specify a new name for the symbol in the Connect database. The original symbol specified under name remains unchanged. Each symbol in the Connect database must have a unique name.
outputSet: string (default: null)
Name of the output set that contains mappings that were actually applied on the symbol labels. Per default no output set is written. Providing a name for the output set indicates that an output set should be written to the Connect database. Note that each symbol in the Connect database must have a unique name. Supported by case, code and regex mode.
The regular expression that needs to match for a label to be replaced.
regex: dictionary (required: case or code or map or regex) (excludes: case, code, map)
Used for executing the LabelManipulator in regex mode to replace labels using a regular expression.
This option can not be specified together with case, code, or map.
A string that specifies the replacement for all labels for which a given pattern in regex mode matches.
rule: string for code, capitalize, lower, upper for case (required)
Can be specified in case and code mode.
case: The type of casing to be applied. Allowed values are:
lower: Change all labels to lower case.upper: Change all labels to upper case.capitalize: Change all labels to a capitalized casing - first letter becomes upper case, all others become lower case.code: A Python function that defines the mapping behavior.
ruleIdentifier: string (default: x)
Specifies the identifier that is used in the rule of the code mode.
A 1-dimensional GAMS set that contains an explicit key-value mapping to replace labels. If
invert: False(default) all labels that match a label of the GAMS set will be replaced by the corresponding set element text.
symbols: all, list of symbols (default: all)
A list containing symbol specific options. Allows to execute the LabelManipulator on a subset of GAMS symbols in the Connect database. The default
allwill apply the LabelManipulator to all symbols of the Connect database.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
Projection
The Projection agent allows index reordering, projection onto a reduced index space, and expansion to an extended index space through index duplication of a GAMS symbol. It can combine these operations, allowing for complex transformations such as simultaneously duplicating some indices, eliminating others, and reordering (e.g. transforming p(i,j,k) to p_new(k,k,j)). For variables and equations a single suffix (.l, .m, .lo, .up, .scale, or .all) or a list of suffixes (e.g. .[l,m,lo,up,scale] or .[all]) can be extracted and written to a parameter. Otherwise, the type of the source symbol determines the type of the new symbol, unless asSet is set to True. If name is a list of scalar symbols of the same type (parameters, variables, or equations), they can be stored in a one-dimensional symbol of the same type with the index label being the name of the scalar symbol.
Here is an example that uses the Projection agent:
Set i / i1*i2 /, j / j1*j2 /;
Parameter
p(i,j) / i1.j1 1, i1.j2 2, i2.j1 3, i2.j2 4 /
s1 / 10 /
s2 / 11 /
s3 / 12 /;
Variable x(i,j);
x.l(i,j) = p(i,j);
embeddedCode Connect:
- GAMSReader:
symbols: all
- Projection:
# 1. reduce index space
name: p(i,j)
newName: p_reduced(i)
aggregationMethod: sum
- Projection:
# 2. reorder index space
name: p(idx1,idx2)
newName: p_reordered(idx2,idx1)
- Projection:
# 3. Extend index space
name: p(i,j)
newName: p_extended(i,j,i)
- Projection:
# 4. variable with single suffix
name: x.l(i,j)
newName: x_level(i,j)
- Projection:
# 5. variable with all suffix
name: x.all(i,j)
newName: x_all(i)
aggregationMethod: last
- Projection:
# 6. parameter as set
name: p(i,j)
newName: p_set(i,j)
asSet: True
text: "from {i} to {j}"
- Projection:
# 7. list of scalars
name: [s1,s2,s3]
newName: p_scalars
- PythonCode:
code: |
print("Parameter p_reduced:\n", connect.container["p_reduced"].records)
print("Parameter p_reordered:\n", connect.container["p_reordered"].records)
print("Parameter p_extended:\n", connect.container["p_extended"].records)
print("Parameter x_level:\n", connect.container["x_level"].records)
print("Parameter x_all:\n", connect.container["x_all"].records)
print("Set p_set:\n", connect.container["p_set"].records)
print("Parameter p_scalars:\n", connect.container["p_scalars"].records)
endEmbeddedCode
In this example, various Projection agents are utilized to demonstrate different projection capabilities:
- The Projection agent is used to project parameter
pto a reduced index space. Aggregation methodsumis selected to aggregate records on the remaining index by taking the sum.Parameter p_reduced: i value 0 i1 3.0 1 i2 7.0 - The Projection agent is used to only reorder the index space of parameter
p. Note that the list of indices specified undernameandnewNameis solely intended to establish the index order for the new symbol and therefore does not need to coincide with the names of the actual GAMS domain sets.Parameter p_reordered: j i value 0 j1 i1 1.0 1 j2 i1 2.0 2 j1 i2 3.0 3 j2 i2 4.0 - The Projection agent is used to project parameter
pto an extended index space by duplicating indexi. The new symbol has an additional indexiwith the same values as the original indexi.Parameter p_extended: i_0 j_1 i_2 value 0 i1 j1 i1 1.0 1 i1 j2 i1 2.0 2 i2 j1 i2 3.0 3 i2 j2 i2 4.0 - A single suffix (
.l) turns the variable into a parameter with only the level values.Parameter x_level: i j value 0 i1 j1 1.0 1 i1 j2 2.0 2 i2 j1 3.0 3 i2 j2 4.0 - The
.allsuffix turns the variable into a parameter with an additional index for the attributes. At the same time the index space is reduced using aggregation methodlast, i.e. only the last record is kept.Parameter x_all: i level_1 value 0 i1 level 2.0 1 i1 marginal 0.0 2 i1 lower -inf 3 i1 upper inf 4 i1 scale 1.0 5 i2 level 4.0 6 i2 marginal 0.0 7 i2 lower -inf 8 i2 upper inf 9 i2 scale 1.0 - The Projection agent is used to turn the parameter into a set (
asSet: True) with customtext.Set p_set: i j element_text 0 i1 j1 from i1 to j1 1 i1 j2 from i1 to j2 2 i2 j1 from i2 to j1 3 i2 j2 from i2 to j2 - A list of scalars is concatenated into a one-dimensional symbol where the index labels are the names of the scalar symbols.
Parameter p_scalars: uni_0 value 0 s1 10.0 1 s2 11.0 2 s3 12.0
Note that many of the Projection capabilities can be combined (e.g. reducing and reordering the index space of a variable while turning the symbol into a parameter using a suffix). The Projection agent can also be used to aggregate duplicate records according to the selected aggregation method.
| Option | Default | Description |
|---|---|---|
| aggregationMethod | null | Specify the aggregation method for the projection. |
| asSet | False | Indicate that the new symbol is a set independent of the type of the source symbol. |
| name | Specify a symbol name with index space and potentially suffix for the Connect database. | |
| newName | Specify a new name with index space for the symbol in the Connect database. | |
| text | null | Element text for resulting sets. |
| trace | 0 | Specify the trace level for debugging output. |
Detailed description of the options:
aggregationMethod: string (default: null)
Specify the method used for aggregation. The default
nullwill not perform any aggregation which might result in duplicate records if at least one index position is projected out. For sets, variables, and equations (without suffix) onlyfirstandlastare meaningful. For parameters, variables, and equations (with suffix) many other aggregation methods are available and meaningful:max,mean,median,min,prod,sem(unbiased standard error of the mean),sum,std(standard deviation),nunique(number of distinct elements),first,last. The projection agent is based on pandasDataFramesand more detailed explanations of the aggregation method can be found at the pandas website.
- Note
- Performing a projection that results in a scalar symbol with multiple values is currently not supported and requires the use of an aggregation method.
asSet: boolean (default: False)
Usually the type of the source symbol and the use of a suffix with variables and equations determine the type of the target symbol. With
asSetset toTruethe target symbol will be a set.
name: string, list of strings (required)
One either specifies a single symbol name with index space and potentially suffix for the Connect database or a list of symbol names of scalar symbols. In the prior case,
namerequires the formatsymName[.suffix](i1,i2,...,iN). The suffix is only allowed on variable and equation symbols and can be either a single suffix (.l,.m,.lo,.up,.scale, or.all) or a list of suffixes in square brackets (e.g..[l,m,lo,up,scale],.[l], or.[all]). If a list of suffixes is provided an additional index is added at the end of the index list that contains the selected attribute labels (e.g.level,marginal,lower,upper, andscale). Using.allis equivalent to.[all]and.[l,m,lo,up,scale]and will always add an additional index. The list of indices does not need to coincide with the names of the actual GAMS domain sets. This index list together with the index list specified fornewNameis solely intended to establish the index order in the symbol specified bynewName. The names in the index list need to be unique. In the latter case (a list of symbol names), the symbols need to be scalar symbols of the same type (parameter, variable, or equation) and a new one-dimensional symbol (of the same type) is created that holds the symbol names as labels.
Specify a new name with index space for the projected or reordered symbol in the Connect database. Note that each symbol in the Connect database must have a unique name.
newNameis given assymName(i1,i2,...,iN). The list of indices does not need to coincide with the names of the actual GAMS domain sets. This index list together with the index list specified fornameis solely intended to establish the index order. Only names that are part of the index list specified fornamecan be used. Unlike the index list forname, the names in the index list fornewNamecan be duplicated. For example:name: p(i,j,k)andnewName: q(k,i,i,k).
Control the handling of element text if the resulting symbol is a set. If set to
"", the text will be dropped. When left at default (None) and the projected symbol is a set, the element text of the original set will be used. For other symbols types, the text will be dropped. Iftextis a string, this string will be assigned to all elements. The string can contain placeholders{i}that will be replaced with the content of the matching index position. For example,text: "{j} - {i}: {element_text}", where{i}and{j}should be index space names in the index space of the symbol name.{element_text}refers to original element text (set) or string representation of a numerical value (parameter or variable/equation with a given suffix) of the source symbol.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
PythonCode
The PythonCode agent allows to execute arbitrary Python code. From within the code, it is possible to access the GAMS database via gams.db (if the PythonCode agent is running in a GAMS context) and the Connect database via connect.container. The GAMS database is an instance of GamsDatabase, whereas the Connect database is a GAMS Transfer Container object. Furthermore there is a predefined instructions list that can be filled with agent instructions that are automatically executed.
| Option | Default | Description |
|---|---|---|
| code | Python code to be executed. | |
| trace | 0 | Specify the trace level for debugging output. |
Detailed description of the options:
Python code to be executed. The YAML syntax offers the pipe character (
|) for specifying multi-line strings:- PythonCode: code: | print("Print from Python") # insert more Python code hereIt is possible to generate agents by appending individual agent instructions to the Python
instructionslist. Those have to be specified by using Python data structures that match the schema of a specific Connect agent. At the end of the Python code, all instructions from theinstructionslist are automatically executed. The following example shows how to fill theinstructionslist with three ExcelWriter agents that write different parameters (p0,p1,p2) into separate Excel workbooks (data_p0.xlsx,data_p1.xlsx,data_p2.xlsx).- GAMSReader: symbols: all - PythonCode: code: | symbols = [ 'p0', 'p1', 'p2' ] for s in symbols: instructions.append( { 'ExcelWriter': { 'file': 'data_{}.xlsx'.format(s), 'symbols': [{'name': s}] } })Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log generated instructions if any.Using
connect.containerallows to access the Connect database directly in the Python code. Theconnect.containeris a GAMS Transfer Container object and data within the container is stored as pandasDataFrames. Please refer to the documentation of GAMS Transfer to learn more about GAMS Transfer and its functionalities.The following complete example shows how to access and modify Connect container data and manually add a new symbol with the modified data to the Connect container:
Set i /1, 2, 3/ i_mod; $onembeddedCode Connect: - GAMSReader: symbols: all - PythonCode: code: | i_mod_records = [ 'i'+n for n in connect.container["i"].records.iloc[:,0] ] connect.container.addSet("i_mod", ["*"], records=i_mod_records) - GAMSWriter: symbols: - name: i_mod $offembeddedCode display i, i_mod;The first line takes the data of set
iand adds an i at the beginning of each UEL in the first column of theDataFrame. The last line writes the modifiedDataFrameas seti_modto the Connect database.Here is another complete example modifying Connect container data and adding a new symbol with the modified data:
Parameter p; $onEcho > p_raw.csv i,j,2000,2001 i1,j1,1,2 i2,j2,3,4 i3,j3,5,6 $offEcho $onEmbeddedCode Connect: - CSVReader: file: p_raw.csv name: p_raw header: True indexColumns: "1,2" valueColumns: "2:lastCol" - PythonCode: code: | p_records = [ [r[0] + '_' + r[1]] + list(r) for i,r in connect.container["p_raw"].records.iterrows() ] connect.container.addParameter("p", ["*"]*4, records=p_records) - GAMSWriter: symbols: - name: p $offEmbeddedCode display p;In this example, we take the data of parameter
p_rawand insert a column of the concatenated row dimensions into the first column of theDataFrame. The modifiedDataFrameis then added to the Connect container as records for the new symbolp. Here is a display of GAMS parameterp:INDEX 1 = i1_j1 2000 2001 i1.j1 1.000 2.000 INDEX 1 = i2_j2 2000 2001 i2.j2 3.000 4.000 INDEX 1 = i3_j3 2000 2001 i3.j3 5.000 6.000
RawCSVReader
The RawCSVReader allows reading of unstructured data from a specified CSV file into the Connect database. Due to performance issues this agent is recommended for small to medium sized unstructured CSV only. This reader works similarly compared to the RawExcelReader agent. It reads the entire CSV file and represents its content in a couple of GAMS sets:
r / R1, R2, ... /(rows)c / C1, C2, ... /(columns)vs(r,c) / R1.C2 "cell text", ... /(cells with explanatory text)vu(r,c,*) / R1.C1."cell text" "cell text", ...(cells with potential GAMS label)
and a parameter vf(r,c) / R2.C2 3.14, ... / (cells with numerical values). Unlike RawExcelReader cells with a date will be not interpreted and stored in vs and vu. Cells with a string value will be stored in vs. If the string length exceeds the maximum length allowed for elements text, it will be truncated. RawCSVReader will try to represent the cell value as a number and if this succeeds stores the number in vf. Strings of GAMS special values INF, -INF, EPS, NA, and UNDEF as well as TRUE and FALSE will be also converted to its numerical counterpart. It will also try to represent the cell value as a string and stores this as a label in the third position in vu. GAMS labels have a length limitation and hence RawCSVReader automatically shortens the label to fit this limit. RawCSVReader will provide a unique label (ending in ~n where n is an integer for strings exceeding the label length limit) for each string in the CSV file. The full string (if it fits) will be available as the element text of the vu record.
To read a CSV file with the RawCSVReader specify:
- RawCSVReader:
file: data.csv
| Option | Default | Description |
|---|---|---|
| cName | c | Symbol name for columns. |
| columnLabel | C | Label for columns. |
| file | Specify a CSV file path. | |
| readAsString | True | Control the automatic pandas type conversion of cells. |
| readCSVArguments | null | Dictionary containing keyword arguments for the pandas.read_csv method. |
| rName | r | Symbol name for rows. |
| rowLabel | R | Label for rows. |
| trace | 0 | Specify the trace level for debugging output. |
| vfName | vf | Symbol name for cells with a numerical value. |
| vsName | vs | Symbol name for cells with an explanatory text. |
| vuName | vu | Symbol name for cells with a potential GAMS label. |
Detailed description of the options:
Control the name of the set of columns.
columnLabel: string (default: C)
Control the labels for the set of columns (
c).
Specify a CSV file path.
readAsString: boolean (default: True)
Control the type of cells returned by pandas.read_csv. If this is set to
True(default) all cells are returned as string and the agent tries to interpret the string itself. If this is set toFalsepandas will try to infer the type. In such a case the agent can't distinguish between cells with1and1.00because pandas turned the integer1already into a float and the agent has no way for recovering the original cell.
readCSVArguments: dictionary (default: null)
Dictionary containing keyword arguments for the pandas.read_csv method. Not all arguments of that method are exposed through the YAML interface of the RawCSVReader agent. By specifying
readCSVArguments, it is possible to pass arguments directly to thepandas.read_csvmethod that is used by the RawCSVReader agent. For example,readCSVArguments: {sep: ';', encoding_errors: 'replace', keep_default_na: False}.Potentially useful arguments could be:
encoding_errors: How encoding errors are treated (default:'strict').keep_default_na: Whether or not to include the defaultNaNvalues when parsing the data (default:True). By default the following values are interpreted asNaN: empty string, "NaN", "N/A", "NULL", and other common representations of missing data.na_values: Additional strings to recognize asNaN.on_bad_lines: Specifies what to do upon encountering a bad line (a line with too many fields) (default:'error').sep: Character or regex pattern to treat as the delimiter (default:',').skip_blank_lines: IfTrue, skip over blank lines rather than interpreting asNaNvalues (default:True).See pandas.read_csv documentation for more details.
- Attention
- When specifying escape sequences like tabs (
\t) or newlines (\n) as the delimiter, you must enclose the value in double quotes (e.g.sep: "\t"). Standard YAML parsing treats single quotes ('\t') or unquoted strings (\t) as literal two-character strings (a backslash followed by a letter). Because the underlying reader interprets separators longer than one character as a regular expression, using single quotes or unquoted strings will trigger a ParserWarning and force a fallback to a slower parsing engine.
Control the name of the set of rows.
Control the labels for the set of rows (
r).
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames and the cell values and it's processing (potentially large output).trace > 3: Log entire intermediate DataFrames (potentially large output).
Control the name of the parameter for cells with a numerical value.
Control the name of the set for cells with an explanatory text.
Control the name of the set for cells with a potential GAMS label.
RawExcelReader
The RawExcelReader allows reading of unstructured data from a specified Excel file into the Connect database. Due to performance issues this agent is recommended for small to medium sized unstructured Excel files only. This reader works similarly compared to the xlsdump tool. It reads the entire spreadsheet and represents its content in a couple of GAMS sets:
s /S1, S2,.../(workbook sheets)w / Sheet1, Sheet2, ... /(workbook sheets by name)ws(s,w) / S1.Sheet1, S2.Sheet2, ... /(workbook map)r / R1, R2, ... /(rows)c / C1, C2, ... /(columns)vs(s,r,c) / S1.R1.C2 "cell text", ... /(cells with explanatory text)vu(s,r,c,*) / S1.R1.C1."cell text" "cell text", ...(cells with potential GAMS label)
and a parameter vf(s,r,c) / S1.R2.C2 3.14, ... / (cells with numerical values). Cells with a date will be stored in it's string representation in vu and as a Julian date in vf. Cells with a string value will be stored in vs. If the string length exceeds the maximum length allowed for elements text, it will be truncated. Excel offers many other cell value types. RawExcelReader will try to represent the cell value as a number and if this succeeds stores the number in vf. Strings of GAMS special values INF, -INF, EPS, NA, and UNDEF will be also converted to its numerical counterpart. It will also try to represent the cell value as a string and stores this as a label in the fourth position in vu. GAMS labels have a length limitation and hence RawExcelReader automatically shortens the label to fit this limit. RawExcelReader will provide a unique label (ending in ~n where n is an integer for strings exceeding the label length limit) for each string in the workbook. The full string (if it fits) will be available as the element text of the vu record.
To read an Excel file with the RawExcelReader specify:
- RawExcelReader:
file: data.xlsx
| Option | Default | Description |
|---|---|---|
| cName | c | Symbol name for columns. |
| columnLabel | C | Label for columns. |
| file | Specify an Excel file path. | |
| mergedCells | False | Control the handling of empty cells that are part of a merged Excel range. |
| rName | r | Symbol name for rows. |
| rowLabel | R | Label for rows. |
| sheetLabel | S | Label for workbook sheets. |
| sName | s | Symbol name for workbook sheets. |
| trace | 0 | Specify the trace level for debugging output. |
| vfName | vf | Symbol name for cells with a numerical value. |
| vsName | vs | Symbol name for cells with an explanatory text. |
| vuName | vu | Symbol name for cells with a potential GAMS label. |
| wName | w | Symbol name for workbook sheets by name. |
| wsName | ws | Symbol name for workbook map. |
Detailed description of the options:
Control the name of the set of columns.
columnLabel: string (default: C)
Control the labels for the set of columns (
c).
Specify an Excel file path.
mergedCells: boolean (default: False)
Control the handling of empty cells that are part of a merged Excel range. If
False, the cells are left empty. IfTrue, the merged value is used in all cells. Note that setting this option toTruehas an impact on performance since the Excel workbook has to be opened in a non-read-only mode that results in non-constant memory consumption (no lazy loading).
Control the name of the set of rows.
Control the labels for the set of rows (
r).
sheetLabel: string (default: S)
Control the labels for the set of workbook sheet (
s).
Control the name of the set of workbook sheets.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames and the cell values and it's processing (potentially large output).trace > 3: Log entire intermediate DataFrames (potentially large output).
Control the name of the parameter for cells with a numerical value.
Control the name of the set for cells with an explanatory text.
Control the name of the set for cells with a potential GAMS label.
Control the name of the set of workbook sheets by name.
Control the name of the set of the workbook map.
SQLReader
The SQLReader agent allows to read symbols (sets and parameters) from a specified database management system (DBMS) into the Connect database. The SQLReader provides DBMS specific connection types for fast and efficient communication with MS-Access, MySQL, Postgres, SQLite and SQL Server (MS-SQL), as well as the generic connection types, PyODBC and SQLAlchemy, that allow to connect to various DBMS if the required database drivers are installed on the system. The SQLAlchemy connection type is based on pandas.DataFrame class' I/O API method read_sql. See getting started example for a simple example that uses the SQLReader.
- Note
- The connectivity to MS-Access databases is available on Windows only and requires a 64-bit MS-Access ODBC driver. See connection for more information.
| Option | Scope | Default | Description |
|---|---|---|---|
| connection | root | Connection dictionary to specify credentials for the database. | |
| connectionArguments | root | null | Dictionary containing keyword arguments for the connect constructor of the respective SQL library or for the sqlalchemy.create_engine constructor. |
| connectionType | root | sqlite | Specify the connection type that will be used to connect to the database. |
| dTypeMap | root/symbols | null | Dictionary used to specify the dtype of columns. |
| indexSubstitutions | root/symbols | null | Dictionary used for substitutions in the index columns. |
| name | symbols | Specify the name of the symbol in the Connect database. | |
| query | symbols | Specify the SQL query. | |
| readSQLArguments | root/symbols | null | Dictionary containing keyword arguments for the pandas.read_sql method. |
| symbols | root | Specify symbol specific options. | |
| trace | root | 0 | Specify the trace level for debugging output. |
| type | root/symbols | par | Control the symbol type. |
| valueColumns | symbols | infer | Specify columns to get the values from. |
| valueSubstitutions | root/symbols | null | Dictionary used for mapping in the value column of the DataFrame. |
Detailed description of the options:
connection: dictionary (required)
Allows to specify the credentials to access the database. Below are examples for connection dictionaries based on the selected connectionType.
sqlite:
connection: {'database': 'absolute//path//to//datafile.db'}mysql/sqlserver:
connection: {'user': <username of the database server>, 'password': <password>, 'host': <hostname or ip address>, 'port': <port number of remote machine>, 'database': <database name>}postgres:
connection: {'user': <username of the database server>, 'password': <password>, 'host': <hostname or ip address>, 'port': <port number of remote machine>, 'dbname': <database name>}
- Note
- Since GAMS 54, the
Postgresdriverpsycopg2has been dropped in favour ofpsycopg(3)for better platform support. As a result, some keys in theconnectionor theconnectionArgumentsoptions can now be different, e.g.databasemust be replaced bydbname. Please refer to the psycopg documentation for more details.access:
connection: {'DRIVER': 'Microsoft Access Driver (*.mdb, *.accdb)', 'DBQ': 'absolute//path//to//datafile.db'}
- Note
- The connectivity to MS-Access databases is available on Windows only and requires a 64-bit MS-Access ODBC driver. If no MS-Access is installed or a 32-bit version of MS-Access, download and install a 64-bit MS-Access ODBC Driver as a redistributable package from Microsoft (e.g. MS-Access 2013 Runtime_x64).
sqlalchemy:
Use
connectionType: sqlalchemyto connect to various databases. Note that the argumentdrivername: <dialect+driver>is required.For dialect SQLite:
connection: {'drivername': 'sqlite', 'database': 'absolute//path//to//datafile.db'}For dialect Postgres:
connection: {'drivername': 'postgresql+psycopg', 'username': <username>, 'password': <password>, 'host': <hostname or ip address>, 'port': <port number of remote machine>, 'database': <database name>}For dialect MySQL:
connection: {'drivername': 'mysql+pymysql', 'username': <username>, 'password': <password>, 'host': <hostname or ip address>, 'port': <port number of remote machine>, 'database': <database name>}For dialect SQL Server:
connection: {'drivername': 'mssql+pymssql', 'username': <username>, 'password': <password>, 'host': <hostname or ip address>, 'port': <port number of remote machine>, 'database': <database name>}For dialect MS-Access:
connection: {'drivername': 'access+pyodbc', 'query': {'odbc_connect': 'DRIVER={Microsoft Access Driver (*.mdb, *.accdb)};DBQ=absolute//path//to//datafile.db;'}}
- Note
- Connecting to databases other than MySQL, Postgres, SQLite and SQL Server through SQLAlchemy requires the respective driver of that database to be present on the system. For the MS-Access dialect, sqlalchemy-access must be installed on the system.
pyodbc:
Use
connectionType: pyodbcto connect any database that provides an ODBC (Open Database Connectivity) driver. Therefore, either specify the DSN (Data Source Name):connection: {'DSN': <Data Source Name>}or insert the connection information directly:
connection: {'user': <username>, 'password': <password>, 'host': <hostname or ip address>, 'port': <port number of remote machine>, 'database': <database name>, 'driver': <name of the ODBC driver>}
connectionArguments: dictionary (default: null)
Dictionary containing keyword arguments for the
connectconstructor of the respective SQL library or for thesqlalchemy.create_engineconstructor.
connectionType: access, pyodbc, mysql, postgres, sqlalchemy, sqlite, sqlserver (default: sqlite)
Specify the connection type that will be used to connect to the database.
The connection type
pyodbcallows to connect to any DBMS that provides an ODBC (Open Database Connectivity) driver. The user is responsible that the required ODBC drivers are installed on the system. For Windows systems, the requiredpyodbcPython library is already included in the GAMS distribution. For non-Windows systems, the user is responsible for installing pyodbc and handling any other dependencies.The connection type
sqlalchemyallows to connect to various DBMS by providing the appropriate dialect and driver. The user is responsible that the required database drivers are installed on the system. Following database drivers are already included in the GAMS distribution: psycopg, pymssql, pymysql and pyodbc (on Windows only).
- Note
- If additional Python libraries need to be installed, one can either extend GMSPython or use an external Python 3 installation that provides the required libraries.
dTypeMap: dictionary (default: null)
Allows to specify the dtype of columns in a dictionary as
key: valuepairs, i.e.<column>: <dtype>.
indexSubstitutions: dictionary (default: null)
Dictionary used for substitutions in the index columns. Each key in
indexSubstitutionsis replaced by its corresponding value. This option allows arbitrary replacements in the index columns.
Name of the symbol in the Connect database. The name must be unique for each symbol.
Specify the SQL query which will fetch the desired table from the database system.
readSQLArguments: dictionary (default: null)
Dictionary containing keyword arguments for the pandas.read_sql method. Not all arguments of that method are exposed through the YAML interface of the SQLReader agent. By specifying
readSQLArguments, it is possible to pass arguments directly to thepandas.read_sqlmethod that is used by the SQLReader agent ifconnectionType: sqlalchemy. If the connection type is notsqlalchemy, this option can be used to parameterize the SQL query. A small example showing how this option can be used is given below.query: "SELECT i,j FROM stock_table WHERE value_col > %(value)s" readSQLArguments: {'value': 10}
- Note
- Different DBMS use different parameter markers and some do not support named parameter markers, e.g.
PyODBC.
symbols: list of symbols (required)
A list containing symbol specific options.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
Control the symbol type. Supported symbol types are
parfor GAMS parameters andsetfor GAMS sets.
valueColumns: infer, lastCol, none, list of strings (default: infer)
Specify columns to get the values from. The value columns contain numerical values in case of a GAMS parameter and set element text in case of a GAMS set. The columns are given as column names represented as a list of strings. For example:
valueColumns: ["i1", "i2"]. If there is more than one value column specified, the column names are stacked to index automatically. As string one can specify the symbolic constantlastCol(i.e.valueColumns: lastCol) ornone(i.e.valueColumns: none). WhenlastColis passed the last column will be treated as a value column and all the other columns will be treated as index columns. Whennoneis passed all columns will be treated as index columns. Specifyingnoneis only valid for symbol typesetsince symbol typeparrequires at least one value column. The defaultinferuseslastColfor symbol typeparandnonefor symbol typeset.
valueSubstitutions: dictionary (default: null)
Dictionary used for substitutions in the value column. Each key in
valueSubstitutionsis replaced by its corresponding value. The replacement is only performed on the values which is the numerical value in case of a GAMS parameter and the set element text in case of a GAMS set. While it is possible to make arbitrary replacements, this is especially useful for controlling sparse/dense reading.
SQLWriter
The SQLWriter agent allows to write symbols (sets and parameters) from the Connect database to a specified database management system (DBMS). Variables and equations need to be turned into parameters with the Projection agent before they can be written. The SQLWriter provides DBMS specific connection types for fast and efficient communication with MS-Access, MySQL, Postgres, SQLite and SQL Server (MS-SQL), as well as the generic connection types, PyODBC and SQLAlchemy, that allow to connect to various DBMS if the required database drivers are installed on the system. The SQLAlchemy connection type is based on pandas.DataFrame class' I/O API method to_sql. See getting started example for a simple example that uses the SQLWriter.
- Note
- The connectivity to MS-Access databases is available on Windows only and requires a 64-bit MS-Access ODBC driver. See connection for more information.
| Option | Scope | Default | Description |
|---|---|---|---|
| columnEncloser | root | ' | Specify if the database uses special character to enclose column names. |
| connection | root | Connection dictionary to specify credentials for the database. | |
| connectionArguments | root | null | Dictionary containing keyword arguments for the connect constructor of the respective SQL library or for the sqlalchemy.create_engine constructor. |
| connectionType | root | sqlite | Specify the connection type that will be used to connect to the database. |
| dTypeMap | root/symbols | null | Specify if the database has a special data type for text and numerical data type columns. |
| fast | root | False | Accelerate data inserts using some non-standard pragmas. For SQLite only. |
| globalCommit | root | False | Specifies whether all queries are committed together at the end of the process. |
| ifExists | root/symbols | fail | Specify the behavior when a table with the same name exists in the database/schema. |
| insertMethod | root/symbols | default | Specify the insertion method to be used to write the table in the database. |
| name | symbols | Specify the name of the symbol in the Connect database. | |
| schemaName | root/symbols | null | Specify the schema name. |
| skipText | root/symbols | False | Indicate if the set element text will be skipped. |
| small | root | False | Reduce the size of the database by storing UELs in a separate table. For SQLite only. |
| symbols | root | all | Specify symbol specific options. |
| tableName | symbols | Specify the SQL table/relation in the provided database/schema. | |
| toSQLArguments | root/symbols | null | Dictionary containing keyword arguments for the pandas.to_sql method. |
| trace | root | 0 | Specify the trace level for debugging output. |
| unstack | root/symbols | False | Indicate if the last index column will be used as a header row. |
| valueSubstitutions | root/symbols | null | Dictionary used for mapping in the value column of the DataFrame. |
Detailed description of the options:
columnEncloser: string (default: ')
When connecting to a database via
connectionType: pyodbc, this option can be used to specify the character used to enclose column names. If the database uses[]to enclose column names, then the same can be set through this option. For example,columnEncloser: "[]".
connection: dictionary (required)
Allows to specify the credentials to access the database. See SQLReader connection for further details and some examples.
- Note
- The connectivity to MS-Access databases is available on Windows only and requires a 64-bit MS-Access ODBC driver. If no MS-Access is installed or a 32-bit version of MS-Access, download and install a 64-bit MS-Access ODBC Driver as a redistributable package from MS (e.g. MS-Access 2013 Runtime_x64).
connectionArguments: dictionary (default: null)
Dictionary containing keyword arguments for the
connectconstructor of the respective SQL library or for thesqlalchemy.create_engineconstructor.
connectionType: access, pyodbc, mysql, postgres, sqlalchemy, sqlite, sqlserver (default: sqlite)
Specify the connection type that will be used to connect to the database.
The connection type
pyodbcallows to connect to any DBMS that provides an ODBC (Open Database Connectivity) driver. The user is responsible that the required ODBC drivers are installed on the system. For Windows systems, the requiredpyodbcPython library is already included in the GAMS distribution. For non-Windows systems, the user is responsible for installing pyodbc and handling any other dependencies for the local Python installation.
- Note
pyodbcprovides a simple and consistent API to connect to many different databases using the ODBC interface. This introduces the challenge that database specific properties are not taken into consideration. For example, different databases have different escaping syntax in order to escape special characters in column names of a table. Thus, the implementation for connection typepyodbcis kept as a general purpose connector to different databases while not escaping the special characters.The connection type
sqlalchemyallows to connect to various DBMS by providing the appropriate dialect and driver. The user is responsible that the required database drivers are installed on the system. Following database drivers are already included in the GAMS distribution: psycopg, pymssql, pymysql and pyodbc (on Windows only).
- Note
- If additional Python libraries need to be installed, one can either extend GMSPython or use an external Python 3 installation that provides the required libraries.
dTypeMap: dictionary (default: null)
When connecting to a database via
connectionType: pyodbc, this option can be used to specify custom data types for text and numerical data if the database does not support the default assignment which is as follows:dTypeMap: {'float': 'FLOAT', 'integer': 'BIGINT', 'text': 'TEXT'}If the database stores integers using
BIGINTdata type but stores floating point numbers asDOUBLEand text usingBLOBdata type, then the option should take the following key-value pairs,dTypeMap: {'float': 'DOUBLE', 'text': 'BLOB'}. Keys other thanfloat,integer, andtextwill be ignored.
fast: boolean (default: False)
Specify if the SQLWriter should accelerate data inserts using some non-standard pragmas for
connectionType: sqlite. Enabling this option turns off the SQLite journal and the synchronize option which speeds up data inserts but reduces data consistency in case of a program crash.
globalCommit: boolean (default: False)
Specify whether SQLWriter commits all queries at the end of the process. It enables faster execution but rolls back all changes if a failure occurs.
- Attention
- The
globalCommitbehavior may be overridden by database-specific behaviors. For example, MySQL implicitly commits DDL-level queries (e.g. table creation) immediately. As a result, all queries executed up to that point will also be committed.
ifExists: append, fail, replace (default: fail)
Specify the behavior when a table with the same name exists in the database/schema.
insertMethod: bcp, bulkInsert, default (default: default)
Specify the insertion method to be used to write the table in the database.
The insertion method
bulkInsertallows for faster insertion when exporting large amounts of data. It can be used together with connection typesaccess,mysql,postgresandsqlserver(for local SQL Server databases). It creates a temporary CSV file and then imports the file into the database.The insertion method
bcpcan only be used together with connection typesqlserver. It is based on the bulk copy program (bcp) utility of SQL Server and allows for fast insertion when exporting large amounts of data to local and remote SQL Server databases. In order to use the insert methodbcp, the ODBC driver for SQL Server and the bcp utility must be installed on the system. For more information on installing both requirements, refer to the official bcp utility documentation.
- Note
- For MySQL with
insertionMethod: bulkInsertthe optionLOCAL_INFILEmust be enabled on the server.
Specify the name of the symbol in the Connect database.
schemaName: string (default: null)
The
schemaNameoption is used to specify the database schema where objects such as tables or views reside. However, not all databases support schemas. For databases likeaccessandsqlite, defining this option will trigger an error.When using connection types such as
pyodbcorsqlalchemy, schema support depends on the underlying database being connected to. Refer to the documentation of your specific database to verify whether schema constructs are supported.
skipText: boolean (default: False)
Indicate if the set element text will be skipped. If
False, the set element text will be written to the last column of the database table.
small: boolean (default: False)
Reduce the size of the database by storing UELs in a separate table for
connectionType: sqlite. A user-friendly SQL VIEW is created to hide the complexity of the joins. The created tables are accessible through their corresponding SQL VIEW.
- Note
- The SQL VIEW is created with the specified table name, whereas the underlying SQL TABLE is created using the table name with an appended
$.
- Attention
- This option can only be enabled when writing a new SQLite database file. The SQLWriter with activated
smallmode, does not support writing to an existing database.
symbols: all, list of symbols (default: all)
A list containing symbol specific options. The default
allwrites each parameter and set into the specified DBMS where the table name is defined by the name of the symbol.
Name of the SQL table/relation in the provided database/schema.
toSQLArguments: dictionary (default: null)
Dictionary containing keyword arguments for the pandas.to_sql method. Not all arguments of that method are exposed through the YAML interface of the SQLWriter agent. By specifying
toSQLArguments, it is possible to pass arguments directly to thepandas.to_sqlmethod that is used by the SQLWriter agent ifconnectionType: sqlalchemy.
Specify the trace level for debugging output:
trace = 0: No trace output.trace > 0: Log instructions and Connect container status.trace > 1: Log additional scalar output.trace > 2: Log abbreviated intermediate DataFrames.trace > 3: Log entire intermediate DataFrames (potentially large output).
unstack: boolean (default: False)
Indicate if the last index column will be used as a header row.
valueSubstitutions: dictionary (default: null)
Dictionary used for mapping in the value column of the
DataFrame. Each key invalueSubstitutionsis replaced by its corresponding value. The replacement is only performed on the value column of theDataFramewhich is the numerical value in case of a GAMS parameter and the set element text in case of a GAMS set. If GAMS special values should be replaced by custom values, use the string representation (upper case) in the dictionary, i.e.INF,-INF,EPS,NA, andUNDEF. For example, specify{'EPS': 0}to replace GAMS special valueEPSby zero. See the GAMS Transfer documentation for more information on GAMS special values. In contrast to the CSVWriter and the ExcelWriter, the SQLWriter does not automatically convert numerical GAMS special values to their string representation. The actual values depend on the DBMS as well as the connectionType.
Examples
This section provides a collection of more complex examples. For simple examples see section Getting Started Examples.
Connect Example for Excel (executeTool win32.ExcelMerge)
The following example shows how to read and write Excel files in Connect. On Windows with Excel installed, the output sheets are merged back into the input workbook using tool win32.ExcelMerge. The entire code is listed at the end of the example. This model is part of DataLib as model connect05. First, the original matrix a is read using the GAMSReader and is then written to input.xlsx using the ExcelWriter. After clearing symbols i and a in the GAMS database, the ExcelReader is used to read file input.xlsx back in and create parameter a in the Connect database. The Projection agent extracts set i from parameter a. With the GAMSWriter, symbols i and a are written to the GAMS database. The tool linalg.invert calculates the inverse inva of a which is then written to output.xlsx using Connect's GAMSReader and ExcelWriter at execution time. The following lines then check if the code is not executed on a UNIX system and if Excel is available. If both is true, output.xlsx is merged into input.xlsx using tool win32.ExcelMerge and both symbols inva and a can be read from input.xslx with a single instance of the ExcelReader. If the code is executed on a UNIX system and/or Excel is not available, output.xlsx can not be merged into input.xlsx, and both files need to be read to create the symbols inva and a. The last part makes sure that inva is the inverse of a.
set i / i1*i3 /; alias (i,j,k);
table a(i,j) 'original matrix'
i1 i2 i3
i1 1 2 3
i2 1 3 4
i3 1 4 3
;
$onEmbeddedCode Connect:
- GAMSReader:
symbols:
- name: a
- ExcelWriter:
file: input.xlsx
symbols:
- name: a
$offEmbeddedCode
$onMultiR
$clear i a
$onEmbeddedCode Connect:
- ExcelReader:
file: input.xlsx
symbols:
- name: a
- Projection:
name: a(i,j)
newName: i(i)
asSet: True
- GAMSWriter:
symbols: all
duplicateRecords: first
$offEmbeddedCode i a
parameter
inva(i,j) 'inverse of a'
chk(i,j) 'check the product a * inva'
;
executeTool.checkErrorLevel 'linalg.invert i a inva';
embeddedCode Connect:
- GAMSReader:
symbols:
- name: inva
- ExcelWriter:
file: output.xlsx
symbols:
- name: inva
endEmbeddedCode
Scalar mergedRead /0/;
executeTool 'win32.msappavail Excel';
mergedRead$(errorLevel=0) = 1;
if (mergedRead,
executeTool.checkErrorLevel 'win32.excelMerge output.xlsx input.xlsx';
embeddedCode Connect:
- ExcelReader:
file: input.xlsx
symbols:
- name: a
- name: inva
- GAMSWriter:
symbols: all
endEmbeddedCode a inva
else
embeddedCode Connect:
- ExcelReader:
file: input.xlsx
symbols:
- name: a
- ExcelReader:
file: output.xlsx
symbols:
- name: inva
- GAMSWriter:
symbols: all
endEmbeddedCode a inva
);
chk(i,j) = sum{k, a(i,k)*inva(k,j)};
chk(i,j) = round(chk(i,j),15);
display a,inva,chk;
chk(i,i) = chk(i,i) - 1;
abort$[card(chk)] 'a * ainv <> identity';
Connect Example for Excel
The following example shows how to read and write Excel files in Connect. The entire code is listed at the end of the example. This model is part of DataLib as model connect01. The example (inspired by the model herves) reads a 3-dimensional parameter from a spreadsheet that has one row index (code) at the left side of the table and the other row index (labId) at the right of the table. A column index (cut) is at the top of the table. The column index consists of floating-point numbers. The goal it to read the data into GAMS but modify the labels of some sets: Only the first two decimal digits of the elements in cut are significant. Moreover, the labId should be prefixed with an L. A new spreadsheet with the new labels should be written. The layout of the table should remain with the exception of moving the labId column also to the left. Here is a screenshot of the original table:

The following GAMS code uses a separate GAMS program (getdata.gms) to get the raw data from the original spreadsheet. Connect runs inside a compile-time embedded code section and uses the Connect agent RawExcelReader to get the raw Excel data. In some subsequent GAMS code the sets rr and cut[Id] as well as the parameter raw are filled knowing the layout of the table (the code is written in a way that the table can grow). This GAMS program gets executed and instructed to create a GDX file. In a compile-time embedded Connect section the relevant symbols (rr, cutId, and raw) are read from this GDX file. The Projection agent extracts the domain labid from the set rr and some Python code using Connect agent PythonCode makes the label adjustments and sorts the data nicely. The Python code uses the connect.container methods to read from and write to the Connect database. Finally, the GAMSWriter agent sends the data to GAMS. In the main program at execution-time an embedded Connect code section exports the labdata parameter in the required form (after reading it from GAMS with the GAMSReader agent). Here is a screenshot of the resulting table:
In the remainder of the GAMS code another execution-time embedded Connect code is used to read the data back from the newly created spreadsheet using Connect agent ExcelReader. The set rr is created from parameter labdata using the Projection agent and everything is written back to GAMS with Connect agent GAMSWriter. The original data and the data from the newly created spreadsheet are exported to GDX (using execute_unload) and compared to verify that the data is identical by calling gdxdiff.
Set code, labId, cut, rr(code<,labId);
parameter labdata(code,labid,cut);
$onEcho > getdata.gms
* Symbols for RawExcelReader
alias (u,*); Set s,w,r,c,ws(s,w),vs(s,r,c),vu(s,r,c,u); Parameter vf(s,r,c);
$onEmbeddedCode Connect:
- RawExcelReader:
file: labdata.xlsx
- GAMSWriter:
symbols: all
$offEmbeddedCode
* Symbols to be filled
alias (*,code,labId,cut); Parameter raw(code,labId,cut); Set cutId, rr(code,labId)
Set cX(c,cut) 'column index', rX(r,code,labId) 'row index';
Singleton set cLast(c); Scalar lastPos;
loop(ws(s,'ZAg'),
lastPos = smax(vu(s,r,c,u), c.pos); cLast(c) = c.pos=lastPos;
loop(r$(ord(r)>4),
rX(r,code,labId) $= vu(s,r,'C1',code) and vu(s,r,cLast,labId));
loop(c$(ord(c)>1 and not cLast(c)),
cX(c,cut) $= vu(s,'R4',c,cut));
loop((rX(r,code,labId),cX(c,cut)),
raw(code,labId,cut) = vf(s,r,c))
loop(cX(c,cut),
cutId(cut) = yes)
);
option rr<rX;
$offEcho
$call.checkErrorLevel gams getdata.gms lo=%gams.lo% gdx=getdata.gdx
$onEmbeddedCode Connect:
- GDXReader:
file: getdata.gdx
symbols: [ {name: rr}, {name: raw}, {name: cutId, newName: cut} ]
- Projection:
name: rr(code,labid)
newName: labid(labid)
- PythonCode:
code: |
labid_records = sorted([ 'L'+t[0] for t in connect.container['labid'].records.values ], key=lambda t: int(t[1:]))
rr_records = sorted([ (t[0],
'L'+t[1]) for t in connect.container['rr'].records.values ], key=lambda t: int(t[0]))
# Trim elements of set cut to two decimal places
cut_records = sorted([ '{:.2f}'.format(float(t[0])) for t in connect.container['cut'].records.values ], key=float)
labdata_records = [ (t[0],
'L'+t[1],
'{:.2f}'.format(float(t[2])),
t[-1]) for t in connect.container['raw'].records.values ]
connect.container.addSet('labid_mod', ['*'], records=labid_records)
connect.container.addSet('rr_mod', ['*']*2, records=rr_records)
connect.container.addSet('cut_mod', ['*'], records=cut_records)
connect.container.addParameter('labdata', ['*']*3, records=labdata_records)
- GAMSWriter:
symbols: [ {name: labid_mod, newName: labid}, {name: rr_mod, newName: rr}, {name: cut_mod, newName: cut}, {name: labdata} ]
duplicateRecords: first
$offEmbeddedCode
execute_unload 'labdata.gdx', labdata, cut, rr;
* Reintroduce 0 (zeros)
labdata(rr,cut) = labdata(rr,cut) + eps;
execute 'rm -f labdatanew.xlsx';
* Write new workbook with good table
embeddedCode Connect:
- GAMSReader:
symbols: [ {name: labdata} ]
- ExcelWriter:
file: labdatanew.xlsx
valueSubstitutions: {EPS: 0}
symbols:
- name: labdata
range: ZAg!A4
endEmbeddedCode
option clear=rr, clear=labdata;
embeddedCode Connect:
- ExcelReader:
file: labdatanew.xlsx
symbols:
- name: labdata
rowDimension: 2
range: ZAg!A4
- Projection:
name: labdata(code,labid,cut)
newName: rr(code,labid)
asSet: True
- GAMSWriter:
symbols: all
duplicateRecords: first
endEmbeddedCode
execute_unload 'labdatanew.gdx', labdata, cut, rr;
execute.checkErrorLevel 'gdxdiff labdata.gdx labdatanew.gdx > %system.NullFile%';
Connect Example for CSV
The following example shows how to read and write CSV files in Connect. The entire code is listed at the end of the example. This model is part of DataLib as model connect02. It starts out with defining some data (stockprice) in a table statement in GAMS. With compile-time embedded Connect code utilizing the GAMSReader agent to bring this data into Connect and exporting it as a CSV file with agent CSVWriter. The GDXWriter agent also creates a GDX file with the data which is then used in a subsequent call to feed gdxdump that produces the same CSV file as CSVWriter. The text comparison tool diff is used to compare the two CSV files. The CSV file look as follows:
"date_0","AAPL","GOOG","MMM","MSFT","WMT" "2012-20-11",12.124061,314.008026,60.966354,21.068886,46.991535 "2112-20-11",12.139372,311.741516,60.731037,20.850344,47.150307 "2212-20-11",12.203673,313.674286,61.467381,20.890808,46.991535 "2312-20-11",12.350039,315.387848,62.401108,21.068886,47.626663 "2712-20-11",12.448025,318.929565,62.461876,21.076981,47.499634 "2812-20-11",12.328911,318.655609,61.604042,20.898905,47.420238 "2912-20-11",12.404848,320.000549,62.332813,21.060795,47.626663 "3012-20-11",12.401172,321.744019,62.044331,21.012224,47.444057
In remainder of the example this CSV file is read back via the Connect agent CSVReader. The code also utilizes the tool csvread to read the CSV file into a GDX file. The code compares the results of both methods. CSVRead also creates sets with the index elements as Dim1, Dim2, ... Therefore, Connect utilizes the Projection agent to extract the index sets date and symbol from the parameter stockprice as sets Dim1 and Dim2. The Connect agent GDXWriter creates a GDX file of the Connect database which then can be compared with the GDX file created by csvread. The GDX comparison tool gdxdiff is used to compare the two GDX files.
Set date,symbol;
Table stockprice(date<,symbol<)
AAPL GOOG MMM MSFT WMT
2012-20-11 12.124061 314.008026 60.966354 21.068886 46.991535
2112-20-11 12.139372 311.741516 60.731037 20.850344 47.150307
2212-20-11 12.203673 313.674286 61.467381 20.890808 46.991535
2312-20-11 12.350039 315.387848 62.401108 21.068886 47.626663
2712-20-11 12.448025 318.929565 62.461876 21.076981 47.499634
2812-20-11 12.328911 318.655609 61.604042 20.898905 47.420238
2912-20-11 12.404848 320.000549 62.332813 21.060795 47.626663
3012-20-11 12.401172 321.744019 62.044331 21.012224 47.444057
;
* Use Connect CSVWriter to write GAMS data in CSV format moving the symbol index into the column (unstack: True)
$onEmbeddedCode Connect:
- GAMSReader:
symbols: [ {name: stockprice} ]
- GDXWriter:
file: sp_connect.gdx
symbols: all
- CSVWriter:
file: sp_connect.csv
name: stockprice
header: True
unstack: True
quoting: 2
$offEmbeddedCode
* Use gdxdump to create a CSV file and text compare the Connect and gdxdump CSV files
$call.checkErrorLevel gdxdump sp_connect.gdx output=sp_gdxdump.csv symb=stockprice format=csv columnDimension=Y > %system.NullFile%
$call.checkErrorLevel diff -q sp_connect.csv sp_gdxdump.csv > %system.nullFile%
* Use Connect CSVReader to read the newly created CSV file and deposit the result in a csvread compatible format
$onEmbeddedCode Connect:
- CSVReader:
file: sp_connect.csv
name: stockprice
indexColumns: 1
valueColumns: "2:lastCol"
- Projection:
name: stockprice(date,symbol)
newName: Dim1(date)
asSet: True
- Projection:
name: stockprice(date,symbol)
newName: Dim2(symbol)
asSet: True
- GDXWriter:
file: sp_connect.gdx
symbols: all
duplicateRecords: first
$offEmbeddedCode
* Use CSVRead to create a GDX file and compare the Connect and CSVRead GDX files
$call gamstool csvread sp_connect.csv id=stockprice index=1 values=2..lastCol useHeader=yes gdxout=sp_csvread.gdx > %system.NullFile%
$call.checkErrorLevel gdxdiff sp_connect.gdx sp_csvread.gdx > %system.NullFile%
Command Line Utility gamsconnect
The GAMS system directory contains the utility gamsconnect to run Connect instructions directly from the command line. On Windows the utility has the callable extension .cmd. This script wraps the Python script connectdriver.py by calling the Python interpreter that ships with GAMS. gamsconnect operates as the other Connect drivers on a YAML instruction file. The agents GAMSReader and GAMSWriter are not available from gamsconnect and will trigger an exception. Substitutions can be passed to gamsconnect via command line arguments as key=value, e.g. filename=myfile.csv and even gams.scrdir=/tmp/. gamsconnect is called like this:
gamsconnect <YAMLFile> [key1=value1 [key2=value2 [key3=value3 [...]]]]
Advanced Topics
Concept of Case Sensitivity
This section describes the general concept of case sensitivity in Connect. Connect is a YAML and Python based framework and is therefore case sensitive. The case sensitivity provides Connect users with a better control of arbitrary data that does not necessarily come in a GAMS compatible format. Many agents allow users to clean up, manipulate or transform data in other ways where case sensitivity provides the most flexibility. However, since Connect has many GAMS dependencies (GAMS is case insensitive) and processes data from many other data formats that have their own concept of case sensitivity, there are some exceptions:
- GAMS related operations (e.g. dropDomainViolations, duplicateRecords).
- Symbol names in the Connect database. Example: A symbol
pin the Connect database can be accessed via symbol nameporP. And ifpexists already, a Connect agent can not create a new symbolP. - Due to the case insensitivity of symbol names in the Connect database, the index list of the DomainWriter option name is also processed case insensitive. In contrast to Concatenate or Projection where the index list is solely intended to establish the index order, the DomainWriter needs to access sets in the Connect database in order to establish regular domains.
- The behavior can sometimes be case insensitive due to the data source/target (e.g. range, index, ignoreColumns).
- The behavior can sometimes be case insensitive due to the operating system (e.g. the
fileoption is case insensitive on Windows). - The behavior can sometimes be case insensitive due to other Python libraries used (e.g. readCSVArguments passes key-value pairs directly to pandas).
This implies that most Connect operations are done case sensitive. For instance, agents like Filter, LabelManipulator or Projection operate case sensitive. Consider the following example that uses the Projection agent:
$onecho > p.csv
i1,j1,2.5
i1,j2,1.7
i2,j1,1.8
I2,j2,1.4
$offEcho
Set i;
Parameter p_reduced(i<);
$onEmbeddedCode Connect:
- CSVReader:
header: False
file: p.csv
name: p
indexColumns: [1,2]
valueColumns: 3
- Projection:
name: p(i,j)
newName: p_reduced(i)
aggregationMethod: first
- PythonCode:
code: |
print(connect.container['p_reduced'].records)
- GAMSWriter:
symbols:
- name: p_reduced
duplicateRecords: first
$offEmbeddedCode
display p_reduced;
Since Projection aggregates case sensitive, both records I2 1.4 and i2 1.8 are kept:
0 value 0 I2 1.4 1 i1 2.5 2 i2 1.8
From a GAMS (case insensitive) perspective these two records are duplicates. Therefore, duplicateRecords must be set when writing symbol p_reduced to GAMS. With duplicateRecords: first only the first duplicate record is kept.
Case sensitivity also holds for substituting indices or values. Consider the following example where the index j2 should be substituted by ABC when reading the CSV file p.csv:
$onecho > p.csv
i1,j1,2.5
i1,J2,1.7
i2,j1,1.8
i2,j2,1.4
$offecho
Set i,j;
Parameter p(i<,j<);
$onEmbeddedCode Connect:
- CSVReader:
file: p.csv
name: p
indexColumns: [1,2]
valueColumns: [3]
header: false
indexSubstitutions: { j2: ABC }
- GAMSWriter:
symbols: all
$offEmbeddedCode
display i, j, p;
Since substituting indices is done case sensitive, the index J2 will not be substituted.
j1 J2 ABC i1 2.500 1.700 i2 1.800 1.400
Text Substitutions in YAML Instructions
In many cases one would like to parameterize the text in the Connect instructions. For example, some of the Connect agents require a file name. Instead of hard coding the file name into the YAML instructions, text substitutions allow to have a place holder for the attribute that is substituted out before giving the instructions to Connect. The place holder in the YAML instructions uses the syntax %SOMETEXT%, similar to the GAMS compile-time variables. For example:
- CSVReader:
file: %MYFILENAME%
name: distance
indexColumns: [1, 2]
valueColumns: [3]
Depending on how Connect runs, the substitution is done in various ways. The section Substitutions in Embedded Connect Code described the substitution mechanisms for embedded Connect code. When Connect is initiated via the command line parameters connectIn or connectOut, the user defined parameter specified by double-dash command line parameters and the given GAMS command line parameters, e.g. %gams.input% will be substituted in the YAML file. The list of parameters available for substitution is printed to the GAMS log at the beginning of the job in the section GAMS Parameters defined.
When Connect is initiated via the shell command gamsconnect all substitutions need to be specified on the command line:
gamsconnect myci.yaml key1=val1 key2=val2 ...
key can be just MYFILENAME or be composed like gams.Input or system.dirSep.
Encoding of YAML Instructions
All instructions provided to the Connect framework are read using UTF-8 encoding (utf-8-sig). This can be customized by adding a comment in the format # coding=<encoding name> or # -*- coding: <encoding name> -*- as first line in the YAML code. Note that UTF-16 encoding is not supported.
Sorting Behavior of Connect Agents
A note on the sorting behavior of Connect agents. All reader and transformer agents do not guarantee a specific order of the created symbol records. However, as the symbol records in the Connect database are saved in categorical data structures, the order in the data source is preserved in ordered categories. All writer agents guarantee that symbol records are written in the order of the categories. Here is an example:
$onecho > ijk_in.csv
i,j,k1,k2
i1,j2,,3
i2,j1,4,
i1,j1,1,2
i2,j2,5,6
$offecho
embeddedCode Connect:
- CSVReader:
file: ijk_in.csv
name: ijk
valueColumns: "3:lastCol"
indexColumns: [1,2]
- PythonCode:
code: |
sym = connect.container["ijk"]
print("ijk records in the Connect database after reading:\n", sym.records)
data_sorted = sym.records.sort_values(sym.records.columns[:-1].tolist())
print("ijk records sorted according to categories:\n", data_sorted)
sym.reorderUELs(uels=['j1','j2'], dimensions=1)
data_sorted = sym.records.sort_values(sym.records.columns[:-1].tolist())
print("ijk records sorted according to reordered categories:\n", data_sorted)
- CSVWriter:
file: ijk_out.csv
name: ijk
unstack: True
endEmbeddedCode
From the data source ijk_in.csv, the CSVReader creates the symbol records as shown with the first print:
ijk records in the Connect database after reading:
i j level_2 value
0 i1 j2 k2 3.0
1 i2 j1 k1 4.0
2 i1 j1 k1 1.0
3 i1 j1 k2 2.0
4 i2 j2 k1 5.0
5 i2 j2 k2 6.0
The ordered categories are inferred from the data source, therefore the order for column i is ['i1','i2'], for column j ['j2','j1'] and for column k the order of the header ['k1','k2'] is preserved. The categories define the order of the symbol records if sorted:
ijk records sorted according to categories:
i j level_2 value
0 i1 j2 k2 3.0
2 i1 j1 k1 1.0
3 i1 j1 k2 2.0
4 i2 j2 k1 5.0
5 i2 j2 k2 6.0
1 i2 j1 k1 4.0
If the order is not as desired, .reorderUELs() can be used to change the order of the categories, e.g. to ['j1','j2'] for column j:
ijk records sorted according to reordered categories:
i j level_2 value
2 i1 j1 k1 1.0
3 i1 j1 k2 2.0
0 i1 j2 k2 3.0
1 i2 j1 k1 4.0
4 i2 j2 k1 5.0
5 i2 j2 k2 6.0
The CSVWriter automatically sorts the symbol records according to the categories (note that the order of column j was changed with the PythonCode agent) and therefore, the content of file ijk_out.csv looks as follows:
i,j,k1,k2 i1,j1,1.0,2.0 i1,j2,,3.0 i2,j1,4.0, i2,j2,5.0,6.0
Use Connect Agents in Custom Python Code
Instead of passing instructions via one of the Connect interfaces, users can execute them directly in their Python code by creating an instance of ConnectDatabase and calling method .execute(instructions). The instructions argument is expected to be either a Python dictionary of form:
{
'<agent name>':
{
'<root option1>': <value>,
'<root option2>': <value>,
... ,
'<root option3>':
[
{
'<option1>': <value>,
'<option2>': <value>,
...
},
{
'<option1>': <value>,
'<option2>': <value>,
...
},
...
]
}
}
or a list of such dictionaries in case multiple Connect agents need to be executed. Users can either construct the Python dictionary themselves or let YAML create the dictionary from a YAML script. The following example creates an instance of ConnectDatabase and executes two agents: First, the CSV file stockprice.csv is read into the Connect database and second, the symbol stockprice is written to the GAMS database. In this example, the agent instructions are directly specified as Python dictionaries.
Set dates, stocks;
Parameter stockprice(dates<,stocks<);
$onEcho > stockprice.csv
date;symbol;price
2016/01/04;AAPL;105,35
2016/01/04;AXP;67,59
2016/01/04;BA;140,50
$offEcho
$onEmbeddedCode Python:
from gams.connect import ConnectDatabase
cdb = ConnectDatabase(gams._system_directory, ecdb=gams)
cdb.execute({'CSVReader': {'file': 'stockprice.csv', 'name': 'stockprice', 'indexColumns': [1, 2],
'valueColumns': [3], 'fieldSeparator': ';', 'decimalSeparator': ','}})
cdb.execute({'GAMSWriter': {'symbols': [{'name': 'stockprice'}]}})
$offEmbeddedCode
display stockprice;
We can also construct the Python dictionaries by using YAML:
Set dates, stocks;
Parameter stockprice(dates<,stocks<);
$onEcho > stockprice.csv
date;symbol;price
2016/01/04;AAPL;105,35
2016/01/04;AXP;67,59
2016/01/04;BA;140,50
$offEcho
$onEmbeddedCode Python:
import yaml
from gams.connect import ConnectDatabase
cdb = ConnectDatabase(gams._system_directory, ecdb=gams)
inst = yaml.safe_load('''
- CSVReader:
file: stockprice.csv
name: stockprice
indexColumns: [1, 2]
valueColumns: [3]
fieldSeparator: ';'
decimalSeparator: ','
- GAMSWriter:
symbols:
- name: stockprice
''')
cdb.execute(inst)
$offEmbeddedCode
display stockprice;
Here YAML creates a list of dictionaries (i.e. a list of agent instructions) from the given YAML script.